


Industry | Network Chips
Model size, Data size의 증가를 고려할 때, Computing Chip을 효과적으로 연결하는 Network Chip의 중요도가 점점 강조되는 중.

AI의 기능은 Large Language Model (LLM) 기반의 언어 관련 기능을 넘어 Multi-modal, Physics 등으로 확장되고 있습니다. 이에 따라 이들을 학습하고, 넓은 범위의 서비스 적용에 필요한 동시다발적인 추론을 수행하는 데 필요한 Computing power는 끊임없이 증가할 것이라고 생각합니다.
이에 따라 Datacenter 1개의 규모는 점차 증가할 것이고, Datacenter의 수 역시 증가할 것이라고 판단됩니다. 즉, Datacenter를 구성하는 요소들을 개발하고 공급하는 사업자들의 구조적인 성장을 기대해볼 수 있습니다. 이번 포스팅에서는 Datacenter의 구성 요소들 중, Processor들이 효과적으로 이용되는 데 필요한 네트워크 반도체에 대해 상세히 살펴봅니다.
Summary
Datacenter는 Package - Rack - Pod - Datacenter로 이루어지는 계층적인 구조를 가지고 있으며, 향후 점점 규모가 커질 AI Model과 Data의 양을 감당하기 위해 더 큰 시스템을 효과적으로 연결하는 네트워크 반도체에 대한 관심이 증가하고 있음. 각 계층에서는 아래와 같은 주요 변화가 발생하는 중.
(이번 포스팅에서 다루지 않음) Package level:
여러 개의 Die를 하나의 Package에 실장하는 Advanced Packaging 기술이 점차 강조되는 중
Die-Die 간 통신을 통합할 UCIe 표준이 등장하며 유관 supply chain의 성장 기대
Rack level → 중요한 Implication을 얻었으나 적합한 기업은 찾지 못함.
PCIe 표준이 점차 설 자리를 잃어가고 있으며, NVLink / Infinity Fabric과 같은 Proprietary Network가 전선을 확대하고 있음
PCIe의 물리 인터페이스를 활용하는 CXL에게도 Rack 내에서는 제한적인 기회가 주어질 것으로 보임. 시장 규모를 확대하기 위해서는 Rack 바깥에 거대한 Memory Pool을 만들고, 이를 Backend Network에 연결하는 아이디어 제안. 이를 구현하기 위해서는 높은 Bandwidth를 가지는 Infiniband/Ethernet - PCIe 변환 Switch 필요. → 아직까지 Player 찾지 못함
무한정 늘어날 수 있는 CXL의 특성을 고려할 때, Elementwise 연산이 가능한 CXL 기반의 PIM 엔진은 Hyperscaler에게 엄청난 인기몰이를 할 것이라고 생각됨. → Samsung, 국내 주요 AI Accelerator의 움직임을 살펴보아야 함
NIC과 DPU의 중요성이 증가하고 있으며, 실제로 Rack 내 GPU당 NIC/DPU 개수는 증가하고 있음. Application specific한 NIC/DPU가 증가할 것이라고 생각하며, 이에 따라 SKU의 숫자가 늘어난 파편화된 시장이 될 것이라고 판단됨
Pod-to-Datacenter level → Broadcom/Nvidia의 변화를 살펴야 함, Fabrinet에 투자 기회가 있을 것
Frontend Network = 스토리지 Pod과 Computing Pod을 연결하는, 데이터 전송에 특화된 Network
Switch IC의 Bandwidth가 증가할수록 Datacenter의 규모를 키우는 데 필요한 비용이 비약적으로 감소. 이에 따라 앞으로 Switch IC는 높은 Bandwidth를 제공할 수 있는 소수 사업자들의 과점 시장이 될 것 → (Top) Broadcom, Nvidia // (Follower) Marvell, Cisco, Intel
Datacenter 규모 증가에 따라 필요한 Optical component의 Q 증가 중. P 감소를 위해 Transceiver의 Digital Signal Processor(DSP)를 제외하는 Linear Direct Drive 기술이 도입되고 있음. 이에 따라 Switch IC와 Transceiver의 Driver / Transimpedence Amplifier의 Interoperability 중요성 증가 → Broadcom - Macom - Arista Networks 협력 구도, Nvidia
Transceiver 당 Bandwidth가 증가하면서 Optical Channel 당 데이터 전송량, Optical Channel의 개수가 모두 증가하고 있는 상황. 이를 생산하기 위해서는 매우 뛰어난 Optical component (Laser, Photodiode, Antireflection coating) 제조 역량, High-precision Assembly 역량 필요. → Fabrinet (Nvidia, Cisco의 Transceiver 위탁 생산) // Broadcom-Arista Neworks의 Transceiver 위탁 생산 중인 기업을 찾아야 경쟁력에 대한 정확한 평가 가능
Loss 최소화를 위한 Co-packaged Optics의 등장. Advanced Packaging 다음 포스팅에서 상세히 다룰 계획
Backend Network = GPU-GPU 등 Accelerator간의 병렬/분산 컴퓨팅을 돕는, 컴퓨팅에 특화된 Network
Infiniband의 운동장이었으나, 최근 Ethernet이 빠르게 시장에 침투하고 있음. 핵심적인 이유는 Hyperscaler들이 Infiniband의 최강자인 Nvidia를 견제하기 위함도 있을 것이라고 판단. Nvidia는 In-network computing으로, Broadcom은 뛰어난 network control 기능으로 경쟁하는 중. → (Infiniband) Nvidia, (Ethernet) Broadcom // 추가로, Ethernet 시장의 유의한 기업들에게 새로운 성장 시장 개척의 기회 발생
Backend Network 역시 Frontend와 마찬가지로 Pod-to-Pod 영역으로 확대되며 Optical Component Q에 높은 성장성을 제공할 것.
Part 1. How a Datacenter Look Like

간략하게 Datacenter의 구조를 설명하자면 위 그림과 같습니다.
DRAM, GPU, CPU, NIC과 같은 개별 단위 Package들이 모여 하나의 Rack을 구성합니다.
여러 개의 Rack은 Top-of-Rack (ToR) Switch를 통해 연결되고, 이렇게 연결된 Rack이 하나의 Pod을 형성합니다.
각 Pod의 ToR Switch를 연결해 그들이 하나의 거대한 시스템으로 운영될 수 있게 만들어진 것이 바로 Datacenter입니다.
이번 포스팅에서는 자세히 다루지 않기에, Package level에서의 변화를 먼저 간단히 정리하자면 다음과 같습니다.

서로 다른 기능을 하는 Die가 하나의 Package 안에 집적되기 시작했습니다. 대표적인 예시가 GPU와 HBM을 연결한 Nvidia의 B100입니다. 메모리와 Processor간의 거리를 줄여 데이터 교환에서 발생하는 속도 저하를 최소화하는 전략입니다. 여기에서 더 확장해, Intel의 Ponte Vecchio는 47개의 Die를 접합했는데요. 다양한 연산이 가능한 Processor들을 하나의 Package에 집적해 보다 복잡한 프로세스를 수행하도록 만들어졌습니다.

파운드리 비용이 급격히 증가하면서 수율 최적화를 위해 Die 한 개의 크기를 줄이는 방향성 역시 제안되고 있습니다. 기존에는 GPU processor die가 하나였다면, 앞으로는 이를 여러 개로 나눈 뒤 하나의 Package 안에 실장하는 디자인이 주류가 될 것으로 보입니다.
위와 같이 Die의 크기를 작게 만들고, 하나의 Package 안에 더 많은 Die를 실장하는 설계 방식을 “Chiplet” 디자인이라고 합니다. 이에 따라, 앞으로 크게 세 가지 방향에서 기술적 해자를 지닌 기업이 탄생할 것이라고 생각합니다. 이번 포스팅에서는 이 내용들을 자세히 다루지 않습니다.
방향 1: Advanced Packaging 기술
방향 2: Package Floorplanning 및 Powerplanning을 지원하는 EDA
방향 3: 다양한 Chiplet을 연결하기 위한 표준 - 현재 가장 유력한 후보군인 UCIe Faciliation을 위한 IP


Part 2. Rack-level Implication

Top 500에서 발표하는 Supercomputer 순위권에 이름을 올린 Frontier, Summit, 작년 Server 판매 기업으로서 AI 수혜의 직격탄을 맞은 Supermicro, Meta의 Grand Teton에 적용된 Rack의 구조는 위 그림과 같습니다. (정확한 구조는 각 링크에서 참조하실 수 있으며, 위 그림은 이해를 돕기 위해 같은 방식으로 각각의 구조를 단순화한 그림입니다.)
각각의 Rack은 동일하지는 않지만, 아래와 같은 유사한 맥락을 공유하고 있습니다.
GPU-GPU interconnect는 Proprietary network를 기반으로 형성되어 있습니다.
GPU Cluster 이외에는 PCIe를 활용해 Flash memory (NVMe)와 NIC, CPU를 연결합니다.

위의 공통적인 특징들을 모아 최근의 슈퍼컴퓨터 Rack이 가지는 구성을 정리하면 위 그림과 같습니다. 결과적으로, GPU Cluster와 이들을 동작하도록 만드는 주변 Package들간의 연결이 나누어진 형태인데요. 저는 위 그림에서의 표현과 같이 Interconnect 진영의 전선이 형성되었다고 생각합니다. 이 전선이 위로 움직일 것인지, 아래로 움직일 것인지가 향후 중요 쟁점이 될 것임이 분명합니다.

Implication 1: 전선은 위로, PCIe 설 자리가 줄어드는 추세

지금까지의 리서치에 따른 제 의견은, Prop network의 강력한 성능으로 인해 PCIe의 전선은 점차 밀려날 것이라는 점입니다. 실제로 위 그림과 같이 Nvidia는 Grace CPU와 H100 GPU를 NVLink를 통해 연결하는 GH200 Supechip을 출시하였습니다. 전선이 위로 이동한 시발점이라고 볼 수 있습니다.
가장 핵심적인 이유는 Bandwidth의 차이입니다. 이 부분은 제가 애독하고 있는 Semianalysis의 “CXL is Dead in AI Era” 포스팅을 참조했습니다. 저자의 분석에 따르면, NVLink/Google ICI 등 Ethernet-style의 SerDes IP가 동일한 면적의 PCIe SerDes IP보다 3배의 Bandwidth를 가진다고 합니다. SerDes IP에 대해서는 다음 파트에서 상세히 다루며, 간단히 이야기하면 전달받은 데이터를 GPU가 이해할 수 있도록 변환하는 역할을 합니다. 즉, 한정되어 있는 Chip 면적에서 PCIe는 상대적으로 적은 데이터 교환을 허락하기 때문에 Chipmaker 입장에서는 성능 확보를 위해 Prop Network를 선택할 수 밖에 없다는 것입니다.
참고로 NVLink의 physical interface는 Ethernet, Infiniband와 interoperable하고, AMD의 Infinity Fabric은 Ethernet Inteface인 OAM에 기반한 PHY를 제공합니다. ( = Ethernet-style의 Network입니다.)
…..The NVSwitch chip is a physical chip similar to a switch ASIC…. The PHY circuit interface is compatible with 400Gbps Ethernet or NDR IB (InfiniBand) connections…. Brief Discussion on NVIDIA NVLink Network
조금은 더 기술적으로 들어가, PCIe SerDes 면적이 Ethernet 기반 SerDes보다 작아질 수는 없을까요? 결론은 “어렵다”입니다. PCIe의 SerDes가 더 넓은 면적을 필요로 하는 이유는 크게 1) 까다로운 Latency 기준, 2) 까다로운 Bit Error Rate 허용 기준 두 가지에서 오는데요. PCIe는 아주 짧은 Latency만을 허용하기 때문에, 미리 오류에 대비하는 Forward Error Correction(FEC)와 같은 전처리 프로세스를 추가하기 어렵습니다. 그런데 Bit Error Rate 역시도 까다롭게 적용하기 때문에 SerDes IP가 “매우 섬세해야” 합니다. 반대로 Ethernet의 경우 Latency 허용 폭이 더 넓어 FEC와 같은 전처리를 보다 폭넓게 적용할 수 있고, 여기에 BER 역시 낮아 SerDes IP가 “조금 덜 섬세해도” 괜찮은 것으로 보입니다. 같은 SerDes를 수행함에 있어 더 섬세한 기능이 필요한 PCIe SerDes에 더 많은 면적이 필요한 것은 자명해 보입니다.

이에 따라 주요 Chipmaker들은 Ethernet 기반의 Prop Network를 더 잘 만들기 위해 노력하고 있습니다. Nvidia의 Mellanox 인수, AMD와 Broadcom의 협력이 그 대표적인 예시입니다. 앞서 언급한대로 Nvidia는 GH200 Superchip을 통해, AMD는 Epic CPU와 Instinct GPU를 연결하는 infinity Architecture platform을 통해 PCIe의 전선을 압박하고 있는 만큼, 상대적으로 응집력이 부족한 PCIe 전선은 후퇴를 거듭할 가능성이 높아 보입니다.

Implication 2: Off-rack Memory Pool이 CXL의 미래
CXL은 PCIe의 물리 인터페이스를 활용하기에, PCIe의 열세는 CXL 진영에 매우 좋지 못한 소식입니다. 그러나 PCIe의 열세와 별개로, CXL의 핵심기능이 가진 경쟁력 측면에서 보아도 On-rack CXL 시장 규모는 한정될 것이라는 것이 제 의견입니다.

CXL의 첫 번째 핵심 기능은 “다른 프로세서의 메모리에 Seamless하게 접근”하는 기능입니다. CXL에서는 이를 CXL.memory, CXL.cache라고 부르는데요. 위 왼쪽 그림과 같이 Processor A에서 Processor B의 Main memory (DRAM)과 Cache memory에 자유롭게 접근할 수 있다는 개념입니다. 그러나 위 오른쪽 그림과 같이 NVLink(& Infinity Fabric)에서도 유사한 기능을 제공하고 있습니다. 앞서 언급한대로 Ethernet 기반의 Prop Network가 Bandwidth에서 유리하다는 측면을 고려하면, 다른 프로세서의 메모리에 접근하는 기능은 CXL만의 경쟁력이라고 보기는 어렵다고 생각합니다.

CXL의 두 번째 핵심 기능은 “굉장히 많은 메모리를 하나의 Pool로 형성해, 많은 Processor가 동시에 같은 메모리에 접근할 수 있도록”하는 기능입니다. 위 왼쪽 그림과 같이 기존 메모리는 Processor 각각에 종속되어 있어 같은 데이터를 여러번 저장해야 했습니다. 또, 메모리의 사용량이 Processor에 배정된 메모리의 양보다 작거나, 애매하게 큰 경우 DRAM Utilization이 작아지는 문제점을 해결하기 어려웠습니다. CXL은 Processor 각각에 배정된 메모리의 양을 줄이고, 더 많은 양의 메모리 Pool을 형성해 1) 불필요한 데이터의 중복 저장을 줄이고, 2) 메모리가 많이 필요한 작업에서도 CPU 여러 대가 불필요하게 멈추지 않도록 지원합니다. Microsoft는 이러한 개념을 이용해 datacenter cost를 효과적으로 줄일 수 있다는 연구 결과를 발표하기도 했습니다. (하지만 두 달이 흐른 뒤, CXL 메모리를 활용할 때 발생하는 Latency와 추가적인 IP cost를 고려하면 오히려 비용 절감 효과보다 비용 추가에 의한 손실이 크다는 연구도 발표합니다. 이는 CXL 적용이 효과적인지에 대한 상당한 논란이 있음을 의미합니다.)
PCIe의 열세가 여기서 강조됩니다. 결국 CXL 메모리 Pool 크기가 시장 규모와 직결될 가능성이 높은데요. Accelerator (GPU)에서 지원하는 PCIe Bandwidth가 제한적이기 때문에 Pool을 늘려봐야 효용성이 떨어지게 됩니다. 즉, Bandwidth의 한계로 인해 효과적인 CXL 메모리 Pool의 크기가 점점 더 작아진다는 것이죠.

저는 CXL이 중요하게 조명받았던 이유는 위 왼쪽 그림과 같이 GPU의 주요 Memory Pool이 CXL이 될 것이라는 가정에서 왔다고 생각하는데요. 위 오른쪽 그림과 같이 GPU의 주요 Pooling 대상이 NVLink로 연결된 다른 GPU HBM들과 Datacenter의 Backend Network로 연결된 다른 Rack의 GPU HBM이 될 가능성이 높아지면서, 위의 가정과는 반대되는 상황이 펼쳐지고 있습니다. 이렇게 되면 CXL의 시장 규모는 본디 전망보다 작아질 수 있습니다. (Backend Network에 대해서는 다음 파트에서 상세히 다루겠습니다.)
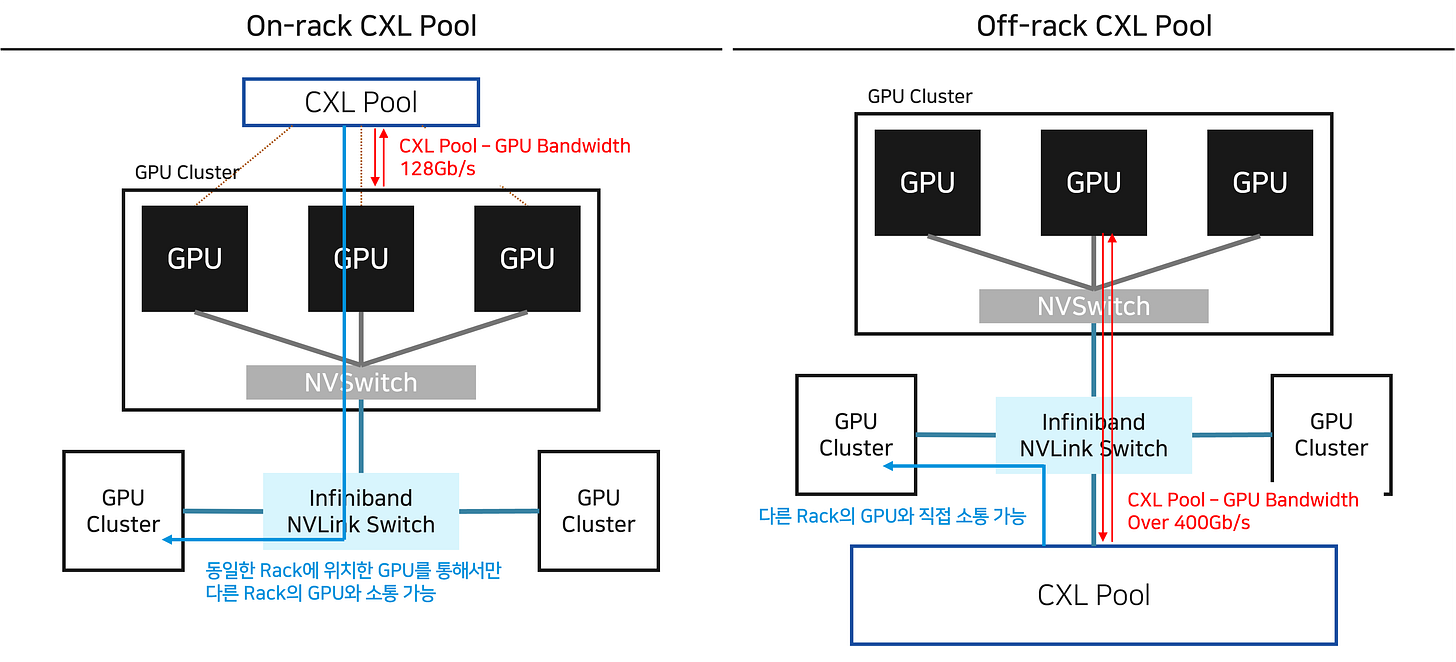
이 문제를 해결할 수 있는 방법은, 저의 개인적인 생각이지만, CXL Pool을 CPU Cluster간의 Backend Network에 연결될 수 있도록 만드는 것입니다. 지금까지 CXL Consortium의 제안은 직접 “주인공” Protocol로 자리매김하는 구조였는데요. 저는 오히려 위 오른쪽 그림과 같이 Interconnect의 주인공 자리를 Infiniband/Ethernet이 가져가도록 하고, Memory Pool의 크기를 극대화해 서로의 장점을 결합해야 한다고 생각합니다. (Infiniband/Ethernet의 높은 Bandwidth와 CXL의 Memory Pooling 기능) 거기에 더해, 기존 Backend Network와 소프트웨어 상에서도 쉽게 결합될 수 있다면 (ex. CUDA를 활용해 제어가 가능하다면) CXL이 GPU (더 넓게는 Accelerator) 시장의 핵심 메모리 Pool로 등극할 수 있다고 생각합니다.
그리고 이를 성공적으로 구현하기 위해서는 Infinband/Ethernet - CXL을 연결하는 고대역폭 Switch IC가 필요할 것이라고 생각합니다. Network Interface에서 복잡한 데이터 경로를 제어하되, 다른 GPU Cluster 간의 데이터 연결 만큼이나 빠르고 넓은 Bandwidth를 제공하기 위해 이들을 꼭 필요합니다. 지금까지의 제 리서치 상에서는 이를 개발하고 있는 기업은 없었습니다. 이러한 Switch IC를 개발하는 데 성공하는 기업이 생긴다면, CXL Memory 역시 Q 증가의 수혜를 기대할 수 있다고 생각합니다.
제가 생각하는 그 다음 모멘텀은 간단한 수준의 Elementwise (Normalization, Activation 등) 연산 능력을 갖춘 Process-In Memory (PIM) 기능의 추가입니다. Elementwise 연산은 보통 모든 데이터 각각에 적용되어야 하기에 Memory 교환 cost가 크지만, 연산히 간단하기에 Computing cost는 작은, 전형적으로 GPU의 효율성을 떨어뜨리는 연산에 속합니다. CXL에서는 메모리 Pool을 무한정 넓힐 수 있는 강점이 있습니다. 이에 따라 PIM이 가능해질 경우 미리 Frontend Network를 통해 스토리지 Rack에서 데이터를 전달받아, GPU에 입력하기 전 Elementwise 연산을 미리 처리해두는 Application Process를 구현할 수 있게 됩니다. GPU 효율성을 극대화해주는 역할로서 Off-rack CXL-PIM pool은 Hyperscaler의 사랑을 받게 될 가능성이 높습니다. (Frontend Network에 관해서는 뒷 파트에서 자세히 다룹니다.)


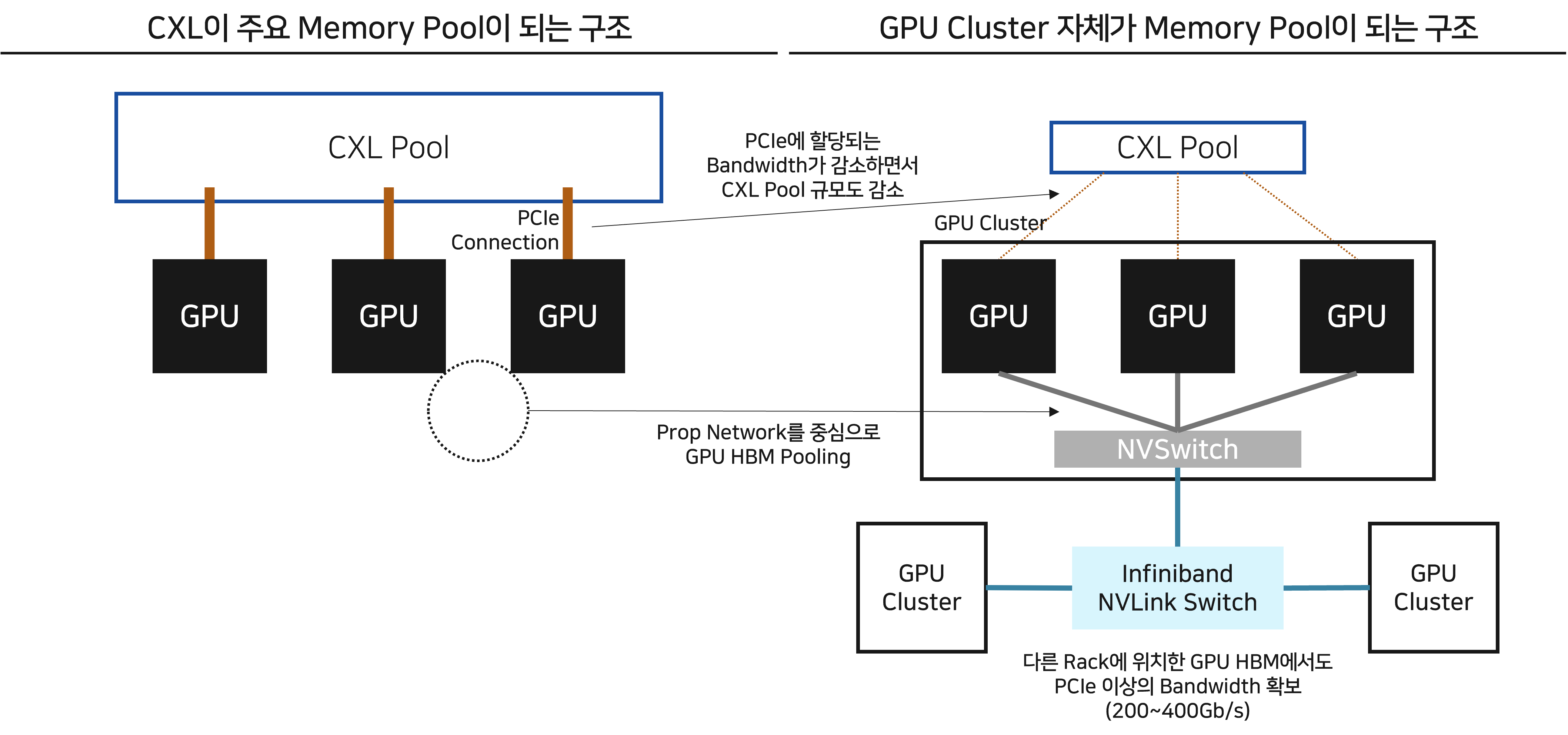

정리하자면,
PCIe 열세와 CXL 기능의 경쟁력으로 인해 rack 안에서의 CXL 기회는 제한적일 것이라고 생각합니다.
이에 따라 Backend Network에 CXL Pool을 직접 연결하는 아이디어를 제안합니다.
Key Enabler는 Infiniband/Ethernet과 CXL을 연결하는 Switch IC입니다. 아직까지 유의한 Player는 제 레이더 안에서 잡히지 않았습니다. (하지만 Ethernet Switch IC와 PCIe Switch IC를 가장 잘 만드는 Broadcom에서 시선을 뗄 수는 없었습니다.)
CXL Pool이 가능해진다면, 그 다음 모멘텀은 CXL 기반의 PIM 엔진입니다. Pool 자체의 크기를(Q) 키우는 한편, 부가 가치(P) 역시도 높일 수 있어 향후 CXL 시장의 성장에 중요한 역할을 할 것이라고 생각합니다.
여기서 한 가지 던져보아야 할 질문이 있습니다. 과연 Nvidia, AMD, Intel 등이 자신들의 Accelerator와 Prop Network에 최적화된 Memory Pooling 기술을 만들 수는 없을까요? 가령, Nvidia가 NVLink를 활용해 접근할 수 있는 Memory Pooling 기술을 SK Hynix와 함께 개발한다고 하면 어떨까요? 과연 여전히 CXL을 기반으로 하는 Memory Pool에 의존할까요? 저는 충분히 가능한 시나리오라고 생각하는데요. 독자 여러분들의 의견도 궁금합니다.
Implication 3: SmartNIC - DPU의 중요성 증가
Network Interface Card (NIC)은 본디 데이터 송/수신 과정을 중재하는 정도의 역할에 그쳤지만, SmartNIC의 시대가 도래하며 CPU에서 수행했던 Packet Processing, Security Coding등의 연산을 대신 수행해주기 시작합니다. 덕분에 CPU는 자신이 잘 하는 복잡한 연산들에 집중하며 흔히 이야기하는 “Datacenter Tax”를 없애주었습니다. 거기에 더해 최근에는 GPU에서 Memory 교환 대비 연산의 강도가 낮아 Computing Utilization을 낮추는 연산을 대신 수행하는 Data Processing Unit (DPU)의 형태로 진화합니다.

DGX-1, DGX-A100, DGX-H100으로 진화하는 과정에서 Nvidia Reference 구조 내의 SmartNIC 개수가 꾸준히 증가하고 있습니다. 여기에는 Nvidia의 ConnectX NIC과 BlueField DPU를 효과적으로 영업하기 위한 전략일 것임을 부정할 수는 없으나, Rack 자체의 Bandwidth 증가를 위해 필요한 변화이기도 합니다. 특히나 DGX-H100 Reference Architecture에서는 GPU 1개와 NIC 1개가 직접적으로 연결되는 구조를 차용해 NIC이 GPU 일부 연산을 Offload하는 역할로 변모하고 있음을 보여줍니다.
이런 상황에서 DPU 개발사들에게 가장 중요한 역량은 “향후 Software (AI model)에서 Offload하고자 하는 연산은 무엇일까?”를 정확히 예측하고 준비하는 것이라고 생각합니다. 다만 저 역시 아직 AI Model의 미래가 어떻게 변할지 상상하고 있는 단계는 아니므로, DPU에 관한 아이디어는 중요성을 강조하는 것에서 마무리하도록 하겠습니다.

지금까지 Rack-level에서의 중요 변화 지점을 살펴보았습니다. 개인적으로 CXL에 관심을 가지고 다양한 아이디어를 만들어 보았는데요. 지금부터는 Pod-Datacenter Level에서의 변화에 대해 살펴보도록 하겠습니다.
Part 3: Pod-Datacenter Level

위 구조는 현재 Datacenter가 주로 차용하고 있는 Nvidia SuperPod의 Clos 구조입니다. Clos 구조 이외에도 Dragonfly 구조나 일전에 TPU 포스팅에서 소개했던 Torus 구조 등이 제안되고 있으며, 어떻게 Pod을 연결하는지 그 구조를 “Network Topology”라고 부릅니다. 다양한 Network Topology의 장/단점에 대해 잘 설명되어 있는 논문을 첨부합니다. 현재로서는 위와 같은 Clos 구조가 확장하기 편리하다는 장점 때문에 주로 활용되고 있습니다.
Pod-Datacenter Level에서의 네트워크는 크게 두 가지로 나뉩니다.
Frontend Network: 데이터의 송/수신을 담당하는 Network입니다. 이들은 보통 NIC - CPU로 데이터를 전달하는 역할을 하고, 처리가 완료된 데이터를 다시 Storage Pod으로 전달하는 역할을 합니다.
Backend Network: 반대로 Distributed Computing을 위해 존재하는 Network입니다. 이들은 GPU 혹은 Accelerator Cluster를 서로 연결하는 역할을 합니다. 최근 들어 가장 큰 변화가 발생하고 있는 지점이기도 합니다.
관련해서는 Marvell Technical Blog에 명료하게 설명되어 있으니 참고하시는 것을 추천합니다.
이번 파트는 Frontend와 Backend 네트워크 각각에서 어떤 변화가 일어나고 있는지에 대해 나누어 설명하고자 합니다.
Part 3-1. Frontend Network

Frontend Network 데이터 송/수신 프로세스와 이에 상응하는 Supply Chain은 위 그림과 같이 정리될 수 있습니다.
Implication 1: Switch IC Bandwidth가 규모 확대의 핵심

Switch는 Rack 사이를 효과적으로 연결하는 Data hub입니다. 위 그림과 같이 4개 Rack으로 구성된 작은 시스템을 switch 없이 직접 연결하면 총 6개의 Interconnect가 필요하지만, Switch를 활용할 경우 4개의 Interconnect 만으로도 연결이 가능해집니다. 이러한 차이는 Rack의 개수가 증가함에 따라 더욱 극대화됩니다.

즉, Switch는 어떤 rack에서 전달 받은 데이터를 정확히 전달하고 싶은 곳으로 보내는 “물류 센터”의 역할을 합니다. Switch가 동시에 처리하는 데이터의 양이 많을수록 - 즉, Bandwidth가 넓을수록 더 적은 Switch로도 동일한 연결성을 만들어낼 수 있게 됩니다. 위 그림과 같이 Switch 하나의 Bandwidth가 2배 증가하면, Switch 개수는 1/6로 줄어들고, 필요한 optical Component 개수 역시 6배 줄어듭니다. Semianalysis의 분석에 따르면, 8,192의 GPU를 연결할 때 51.2Tb/s의 BW를 가진 Switch로 시스템을 구성하면 192개의 Switch가 필요하지만, 25.6Tb/s의 BW를 가진 Switch로 동일한 시스템을 구성하면 448개의 Switch가 필요하다고 이야기합니다. 관련된 광학 부품은 3배 이상 차이가 발생한다고 합니다. 단순한 계산으로, 8,192개 GPU 클러스터 형성 시 51.2Tb/s Switch를 사용했을 때 Transceiver에서 절약할 수 있는 비용이 이미 500억 원이 넘습니다. (= 절감되는 400Gb Transceiver의 수(=16,834 * 2 * 2개) * Average Price 500$) Meta는 20만 개의 GPU에 기반한 시스템을 구축한다고 하는데요, Switch BW의 차이로 인해 1조원이 넘는 CapEx 차이가 발생할 수 있다고 생각할 수 있는 것입니다. 여기에 더해 위 그림처럼 Switch BW가 작아지면 더 많은 Switch를 거쳐야 데이터가 전달되므로, 이를 거치며 누적되는 Latency와 신호 손실(이를 보상하기 위한 신호 복구) 비용을 고려한다면 Switch Bandwidth의 중요성은 더욱 강조됩니다.

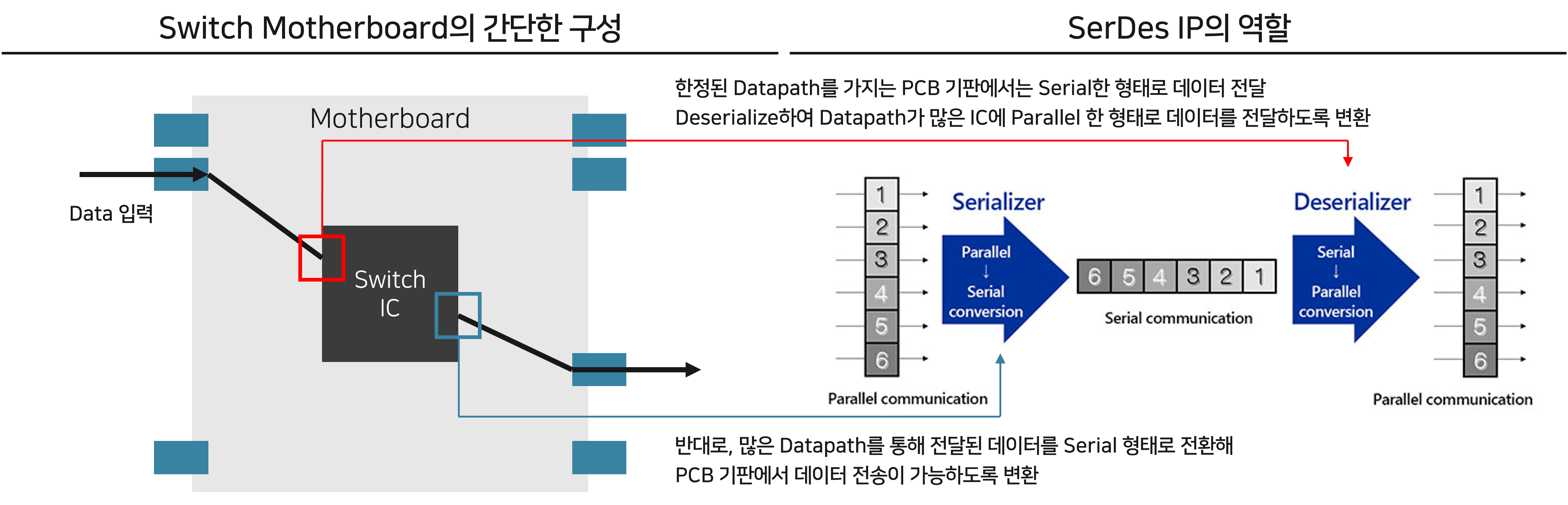
Switch는 위 그림과 같이 구성되어 있습니다. 여기서, PCB 기판 혹은 Cable에는 제한적인 Datapath만이 존재합니다. Switch IC 내에서는 수십nm 이하의 아주 작은 선폭으로 촘촘히 배열된 선을 통해 Data를 전달할 수 있지만, PCB에서는 수십 개 정도의 적은 배선에 모든 데이터를 실어보내야 합니다. 이에 따라 Switch IC에는 병렬로 나열된 데이터를 직렬화시키는 Serialization을 수행해 데이터를 보내고, 다시 그 데이터를 받아 병렬화하는 Deserialization을 수행하는 “SerDes” IP가 배치됩니다. SerDes IP에서 한번에 처리할 수 있는 데이터의 양이 곧 SerDes Bandwidth로 정의되고, 이는 다르게 이야기해 PCB 배선 채널 하나에서 얼마나 많은 데이터가 전달될 수 있는지와 직결됩니다.

과거에는 SerDes당 Bandwidth가 25~50Gb/s 수준에서 머물렀지만, 최근에는 PAM4 방식을 차용해 SerDes당 Bandwidth가 100Gb/s를 상회하였고, 다음 세대에서는 200Gb/s SerDes를 만나볼 수 있을 가능성이 높습니다. Switch IC의 Bandwidth는 따라서, 포함하고 있는 SerDes IP의 성능(Bandwidth)에 Switch IC에 집적된 SerDes IP의 개수를 곱해 얻을 수 있게 됩니다. Broadcom의 대표적인 Switch인 Tomahawk의 Bandwidth와 SerDes IP의 Bandwidth, SerDes IP의 개수는 위 그림과 같이 발전해왔습니다. (PAM4에 대해 쉽게 이해할 수 있는 블로그 글1, 글2를 첨부합니다.)
결과적으로 앞으로는 1) SerDes IP의 Bandwidth를 어떻게 더 넓힐 것인지, 2) SerDes IP의 개수는 어떻게 늘릴 것인지에 대한 기술적 진보가 필요합니다.
Bandwidth의 경우, PAM8 modulation 기술이 등장해야 한다고 생각합니다. 이번 포스팅에서 PAM 기술에 대해서는 자세히 다루지 않습니다. 다만, PAM 기술은 동일한 폭의 차이를 여러 개로 보다 미세하게 쪼개는 역할을 하기 때문에, Lossy한 PCB 기판을 이동할 때의 정보 손실이 필연적입니다. 이에 따라 PCB 기판에서의 데이터 전송을 없애는 Co-packaged Optics (CPO) 기술이 중요하게 언급되기 시작했습니다.
집적화의 경우, Foundry 기술의 확대와 더불어, 앞서 자세히 다루었던 Hybrid Bonding 기술을 통한 3D Stacking이 중요한 기회가 될 것이라고 생각합니다.
이 영역에서는 Broadcom과 Nvidia가 선두를 달리고 있고, Marvell, Cisco, Intel이 뒤를 추격하고 있습니다. 상당히 기술 성숙도가 높고 이미 Consolidation이 진행된 시장이며, 자본 장벽이 높은 기업들이 기술을 고도화하는 만큼, 새로운 기업이 침투하기는 어려운 시장이라고 생각합니다. 그렇기에 위 기업들이 어떤 변화를 가져가는지 상세히 살피면서, Switch 시장 자체보다 유관 시장들의 변화에 대응하는 것이 좋은 투자/사업 전략이 될 것이라고 생각합니다.


Implication 2: 비용 절감을 위한 Linear Direct Drive 제안
Datacenter가 확장됨에 따라, 자연스럽게 Optical component에 투자되는 비용도 증가하고 있습니다. Switch와 Switch를 연결하는 Optical component는 크게 Transceiver와 Cable로 구성되어 있는데요, 이번 포스팅에서는 상대적으로 가격이 비싼 Transceiver에 대해 살펴보겠습니다. Transceiver는 Bandwidth 400Gb/s 기준 500$ 이상, 800Gb/s 기준 800$ 이상의 높은 가격에 판매되고 있습니다. (위 링크에서 판매되는 제품 기준으로 200m 떨어진 두 Switch를 연결하는 것에는 최소 2500$ 이상의 Optical component가 필요하다고 볼 수 있습니다.) 앞선 Implication에서 언급한 바와 같이 Switch IC의 Bandwidth를 높여야 이러한 cost를 효과적으로 절약할 수 있습니다. 그리고 또 다른 하나의 방법은 Transceiver의 가격 자체를 낮추는 것입니다.
Optical Transceiver는 아래 그림과 같이 크게 세 가지 구성 요소로 이루어져 있습니다.

Digital Signal Processor (DSP)
DSP는 아날로그 형태로 전달된 데이터를 다시 디지털 신호로 변환한 뒤, 데이터를 가공해 손실을 복원하고, 다시 이를 아날로그 신호로 변환해 전달하는 역할을 합니다. 이 분야는 Marvell (Inphi)이 가장 뛰어난 기술력을 보유하고 있고, Broadcom, Maxlinear 등이 경쟁하고 있습니다.
Electrical Engine (EE)
신호를 송신할 때 - Driver: DSP로부터 받은 신호를 추가로 가공, Laser가 동일한 데이터를 전달할 수 있도록 drive 전류를 생성하는 역할을 합니다.
신호를 수신할 때 - Transimpedence Amplifier (TiA): Photodiode를 통해 변환되어 전달된 전기 신호를 증폭시켜 DSP로 전달하는 역할을 합니다.
이 분야에서는 Marvell, Macom이 가장 앞선 기술력을 보유하고 있습니다.
Optical Engine (OE)
신호를 송신할 때 - Laser 및 Fiber coupling optics: Driver에서 전달 받은 전류를 기반으로 빛을 생성하는 Laser가 배치됩니다. 그리고 발생한 빛을 광학 케이블에 손실 없이 전달하는 광학 모듈이 구성됩니다. Laser는 하나의 파장만을 발생시키는 Single mode (SM) Laser가 있고, 여러 개의 파장을 발생시키는 Multi mode (MM) laser가 있으며, SM Laser 영역에서는 Lumentum이, MM Laser에서는 Coherent가 가장 뛰어난 기술력을 보유하고 있습니다.
신호를 수신할 때 - Photodiode 및 Prism: Fiber로부터 전달 받은 광학 신호를 섬세하게 align하여 Photodiode에 전달해야 합니다. 그리고 이를 통해 Photodiode는 광학 신호를 전기 신호로 변환하는 역할을 합니다. 제가 아는 한, Photodiode 자체는 commoditize되어 많은 사업자들이 유사한 수준으로 공급하고 있습니다.

이 세 가지 Component 중 DSP를 없애려는 움직임이 확인되고 있습니다. DSP는 기본적으로 신호의 손실을 가정하고, 아날로그 → 디지털, 디지털 → 아날로그로 총 두 차례의 신호 변환을 수반합니다. 이 과정에서 높은 전력과 Latency 손실이 발생하게 됩니다. 또, DSP는 Transceiver 가격의 핵심적인 비중을 차지합니다. Linear Direct Drive (LDD)는 위 그림과 같이 Switch IC의 Error Correction과 SerDes IP를 고도화를 통해 신호의 Integrity를 높여 DSP 없이도 충분히 깔끔하고 정확한 신호가 전달되도록 하는 기술입니다. LDD를 활용할 경우 DSP로 인해 발생한 단점들을 해결할 수 있게 됩니다.
수백 m를 이동하는 장거리 Pod-to-Pod 통신에는 아직 LDD 기술을 활용하기는 어렵습니다. 이에 따라 50m 전후의 근거리 통신에서 LDD가 우선적으로 침투할 것으로 보입니다.
LDD 구현을 위해서는 Switch IC와 Driver/TiA가 서로 Interoperable해야 합니다. 이에 따라 Broadcom은 Macom과 함께 협력해 효과적인 Switch - Driver/TiA 시스템 구축을 준비하기 시작했고, Arista Network도 함께 가세해 Switch Motherboard와 Port도 LDD에 최적화될 수 있도록 기술을 개발하고 있습니다. Nvidia 역시 LDD 기술에 큰 관심을 가지고 있는 것으로 파악되며, LDD를 활용할 경우 DSP 기반 Transceiver를 거칠 때보다 Latency가 비약적으로 줄어든다는 연구 결과를 발표한 적도 있습니다.
LDD의 발전에 있어서 Co-packaged Optics의 중요성은 또 다시 강조될 가능성이 높습니다. 앞서 언급했던 대로, Switch IC와 Port 사이는 지금 PCB 기판을 통하고 있는데요. 여기서 발생하는 신호 손실로 인해 DSP를 사용하는 것이 강제되었던 것입니다. 만약 PCB 기판 없이 Switch IC와 Port가 연결되어 있다면 DSP의 중요성은 더욱 흐릿해질 것이라고 생각합니다.


Implication 3: Optical Engine 제조 기술의 난이도 증가
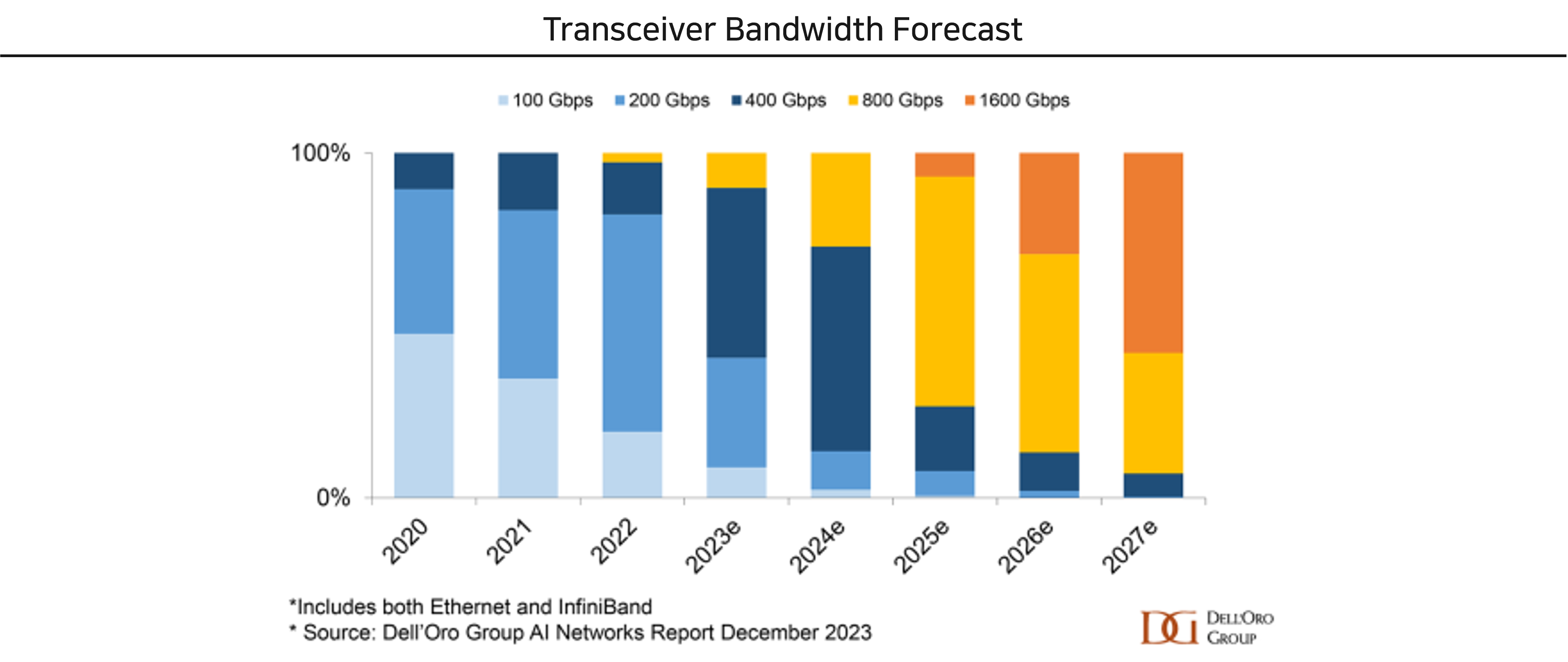
2023년부터 본격적으로 800Gb/s Bandwidth를 가진 Transceiver 시대가 개화했습니다. 위 그림과 같이 향후 시장은 2-3년간 800Gb/s Trasceiver가 주류가 될 것으로 보이며, 그 다음 1.6Tb/s 세대로 전환될 것으로 전망됩니다. Datacenter 내에서 Data communication은 단순 AI 뿐 아니라 점차 확대되고 있는 Online Service에서도 중요하기 때문에, Transceiver의 Bandwidth 증가 흐름은 지속될 가능성이 높다고 생각합니다..

Optical Engine (OE) 중 Transmittance, 데이터를 송신하는 부분은 위 그림과 같은 구조로 구성되어 있습니다. Laser, 정밀 광학 부품, 그리고 그들의 assembly 세 가지가 핵심인데요. 여기서 Laser 하나가 “Optical channel”을 형성합니다. 그리고 Transceiver의 Bandwidth는 “Channel당 데이터의 양 X Optical Channel의 수”로 정의됩니다.
최근 판매되고 있는 800Gb/s Trasceiver 중 일부는 8개의 Optical Channel로 이루어져 있는데요. 이 경우 각각의 Optical Channel은 매 초당 100Gb의 데이터를 전달합니다. 이처럼 8개의 Channel로 구성된 Tranceiver를 OSFP (Octal Small Form Factor Pluggable)라고 부릅니다. 일부는 4개의 Optical Channel로 이루어져 있는데요. 이 규격을 QSFP (Quad Small Form Factor Pluggable)라고 부릅니다.
앞으로 Transceiver의 Bandwidth가 증가하려면, Channel의 개수가 많아지고, 각각의 Channel이 감당하는 데이터의 양 역시 많아져야 합니다. 다르게 이야기해 데이터들을 보다 “정확하게” 전달하는 기술이 점차 중요해질 가능성이 높습니다.
(직접 Fiber coupling 실험을 해 보신 분들이라면 더 잘 아시겠지만)아주 작은 각도와 위치의 차이로도 Coupling Efficiency가 급격하게 떨어지게 됩니다. 하지만 점차 더 많은 수의 Laser를 Fiber에 Coupling 시켜야 하고, 반대로 Channel Bandwidth를 늘리기 위해 PAM X 기술이 강조되며 Coupling Efficiency에 대한 기준은 점점 높아지고 있습니다.이에 따라 향후 OE를 섬세하게 Assembly할 수 있는 기술의 중요성은 점점 증가할 것이라고 생각합니다. 제 리서치에 따르면, 지금 당장 가장 유의한 OE Assembly 기술을 가진 기업은 Fabrinet입니다. Fabrinet은 Laser (Lumentum의 Single Mode Laser), 정밀 광학 부품을 직접 제조한 경험이 있기 때문에 하나의 공장 안에서 Laser / Optics 제조와 Assembly를 전부 수행할 수 있는 몇 안 되는 기업입니다. 지금까지 Nvidia, Cisco의 선택을 받았고, 23년부터 본격적으로 Nvidia향 매출이 유의하게 집계되기 시작하였습니다.

추가로, Broadcom-Arista Network의 Supply Chain에 관해서도 리서치 중에 있습니다. 이들 역시 설계만 수행하고 생산은 위탁하고 있는 만큼, Fabrinet이 선택 받을 가능성도 배제할 수 없습니다. 조금 더 면밀한 리서치가 수반되어야겠지만, 개인적으로는 Fabrinet이 OE 계의 TSMC가 될 가능성도 충분히 존재한다고 생각합니다.


Implication 4: Co-packaged Optics (CPO)
앞서 LDD 기술에 대해 설명하며 언급했던 대로, Lossy한 PCB 기판을 거치지 않는 Co-packaged Optics (CPO) 기술이 Broadcom, Nvidia, Intel을 중심으로 중요하게 언급되고 있습니다. PCB 기판을 거치며 손실된 신호는 또 다른 열원으로 작용하기 때문에, CPO가 실제로 구현된다면 열 발생 감소, DSP 감소로 인한 Cost 감소, DSP로 인한 Latency 감소 등 다양한 장점을 가질 것으로 전망됩니다.

CPO는 위 그림과 같이 PCB 기판 없이, Switch IC가 위치한 Interposer에 직접 OE를 실장하는 기술인데요. 사실상 핵심은 Compact한 OE 제조 기술, 2.5D Packaging 역량입니다. OE 자리에 HBM이 올라가면 GPU라고 생각할 때, 매우 이질감이 느껴지는 기술은 아닙니다. - 다르게 이야기해, 상용화에 긴 시간이 필요해보이지는 않습니다.
다만 기술적으로 볼 때 “광학 신호의 신뢰성있는 연결”이라는 과제를 함께 해결해야 하기 때문에 추가적인 허들이 존재할 수 있습니다. CPO에 대해서는 유리 기판과 함께 Advanced Packaging 포스팅에서 상세히 다루도록 하겠습니다. Teaser의 느낌으로, Broadcom의 영상을 첨부합니다.

Part 3-2. Backend Network
Backend Network는 Frontend Network와 유사한 프로토콜 (Ethernet, Infiniband), 유사한 구조 (Clos 구조)를 가지지만, Frontend Network가 데이터 송/수신 자체를 중점적인 목표로 두었다면 Backend Network는 “Computing”을 연결하는 것이 중점적인 목표입니다. 예를 들어 GPU A에서 연산을 마친 데이터와 GPU B에서 연산을 마친 데이터를 서로 더하려면, 데이터를 GPU B로부터 GPU A로 전달하는 네트워킹이 필요해집니다. 만약 Frontend Network를 통할 경우, GPU A의 HBM에 있는 메모리를 CPU로 전달하고, NIC을 거쳐 Frontend Network를 통해 다른 Rack에 도달한 뒤, 다시 NIC/CPU를 거쳐 GPU HBM에 전달되기 때문에 불필요한 속도 저하 요인이 매우 커집니다. 따라서 병렬 컴퓨팅 혹은 분산 컴퓨팅이 중요해지고 있는 지금 GPU A와 B를 직접 연결해주는 Backend Network의 중요성은 어느 때보다 강조되고 있습니다.

Meta는 위 그림과 같이 Deep learning을 수행하는 과정에서 데이터가 Network 상에 머무르는 시간이 20~60% 수준이라고 언급합니다. 이 시간 동안은 GPU는 흔히 이야기해 “놀고 있는” 상태가 된다는 것입니다. 무지 비싼 돈을 들여 구축한 GPU cluster가 프로그램을 수행하는 전체 시간의 60% 동안 움직이지 않는다면, 그만한 낭비가 없습니다. 이 데이터는 향후 Backend Network에 아직까지 많은 폭의 발전 여지가 남아있음을 보여줍니다.

지금까지 Backend Network를 주도했던 것은 Nvidia 중심의 Infiniband 프로토콜입니다. 하지만 위 그림과 같이 최근 Ethernet이 치고 올라오기 시작해 유의한 시장 침투에 성공한 모양새입니다. 과연 어떤 프로토콜이 승자의 자리를 공고히 하게 될까요?


Implication. In-network computing과 Ethernet의 고도화
Networking의 목적 자체가 “Computing”에 주안점을 두고 있기 때문에, 앞서 살펴본 Frontend Network와 달리 Bandwidth 이외에도 중요한 다른 지점이 발생하기 시작합니다. 대표적인 것이 In-Network Computing입니다.
Nvidia의 Infinband Switch는 Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)라는 Network 상에서 직접 컴퓨팅을 수행하는 In-Network Computing (INC) 프로토콜을 지원합니다. 이는 2016년 Mellanox가 독자적인 기업일 때부터 준비해왔던 기술입니다. 관련해서는 아래 영상을 확인해보시는 것을 추천합니다.
위 영상처럼 INC는 최댓값을 찾거나, 모든 값을 더하거나 평균을 내는 등의 동작을 Network Switch IC에서 수행해줍니다. 이 덕분에 기존에는 데이터가 누적되며 발생했던 Conjestion을 효과적으로 줄이는 한편, ‘Effective Bandwidth’가 증가하게 됩니다. 가령, 위 그림과 같이 동일한 Bandwidth를 가지고 있더라도 기존에는 누적되는 데이터로 인해 더 많은 양의 High-level Switch를 필요로 했었다면, INC를 통해 필요로 하는 High Level Switch 수가 비약적으로 줄어들 수 있습니다.

최근 Nvidia는 Infiniband에만 적용되었던 SHARP를 NVLink Switch까지 확장한다고 발표하였습니다. 그리고 위 그림과 같이 Backend Network의 주요 강자였던 Infinband 대신 NVLink Switch를 활용해 Nvidia GPU를 연결하는 시나리오를 발표합니다. NVLink Switch는 Optical Connection을 기반으로 최대 256개의 H100을 지원하는 구조를 갖추었으나, 아직까지 실제로 생산/판매는 이루어지고 있지 않은 것으로 보입니다.
INC 이외에도 Infiniband Protocol에서는 Remoted Direct Memory Access (RDMA) 등의 기능이 추가적으로 제공되며 GPU의 효과적인 연결 기능을 제공하고 있습니다. RDMA는 최근 RDMA on Converged Ethernet (ROCE) 라는 개념으로 Ethernet에서도 제공되고 있습니다. Infiniband에서 다양할 feature를 제공하고 있는 한편, Ethernet은 이러한 feature를 흡수하는 형태로 발전하고 있습니다.
반대로 Nvidia는 자신들이 구축한 Infiniband에서의 강력한 시장 영향력을 유지하기 위해, 자신들의 시스템과 Infiniband를 모두 차용하겠다고 이야기하는 OEM들에게 더 많은 GPU를 배정하는 전략을 차용하고 있습니다. 이처럼 폐쇄적인 형태의 전략이 향후 Nvidia의 기술적 해자를 공고히 만들지, 혹은 지나친 배타성에 의한 자충수가 될지 지켜보아야 할 것 같습니다.

그런 중에 Nvidia Infiniband에 맞서 Broadcom은 Ethernet 기반의 Jericho switch 시리즈를 고도화하고 있습니다. Jericho는 앞서 언급한 Tomahawk와 비교해 상대적으로 적은 Bandwidth를 가지고 있지만, 더 많은 feature를 통해 seamless한 computing cluster를 구축합니다. Broadcom은 Jericho-3AI가 Nvidia Infiniband 대비해 Nvidia Collective Communications Library (NCCL)의 all-to-all, all reduce 등의 연산에서 10% 뛰어난 성능을 보인다고 주장하고 있습니다. NCCL의 다양한 연산에 대해 잘 설명해둔 블로그를 첨부합니다.
Nvidia가 SHARP 기반의 INC를 통해 성능을 극대화했다면, Jericho는 Load Balancing, Conjestion Control 등을 기반으로 성능을 극대화하는 다른 관점에서의 강점을 내세웁니다. Nvidia는 기존에 잘 하던 Computing을, Broadcom은 기존에 잘 하던 Network control을 적용했다는 것이 흥미롭습니다.
이러한 시장 상황에서 제가 판단하는 중요한 투자 포인트는 다음과 같습니다.
저는 개인적으로 Broadcom의 Ethernet이 빠르게 시장 점유를 증가해갈 것이라고 생각합니다. Nvidia의 독점적인 지위를 원치 않는 Hyperscaler, 상대적으로 가격이 높은 Infiniband 구축 비용 등의 문제가 Broadcom의 Backend Network 시장 침공을 통해 본격적으로 드러날 것이라고 생각합니다. 실제로 반도체 전설 짐 켈러도 이더넷의 중요성을 언급한 적이 있습니다. 이에 따라 Ethernet에서 높은 수준의 기술력을 갖춘 기업들이 기존 Frontend Network에서 데칼코마니처럼 하나의 추가적인 시장을 가져갈 수 있을 것이라고 생각합니다. 아마도 여기서 가장 큰 수혜를 입을 기업이 Broadcom과 긴밀히 협업하는 Arista Networks가 될 가능성이 있다고 생각하고, 이를 증명하듯 최근 연일 신고가를 경신하고 있습니다. (개인적으로 생각하기에 좀 비쌉니다..)
기술적인 부분에서는 두 기업이 Nvidia - AMD처럼 엎치락 뒤치락 치열한 공방전을 벌일 것이라고 생각합니다. 그들이 갖춘 R&D 구조에 따라 다른 기업들은 그 속도를 따라오기 쉽지 않을 것이라고 생각합니다.
Ethernet이 시장 점유율을 늘려가든, Infiniband가 이를 잘 방어해내든, 두 프로토콜 모두 Pod-to-Pod 연결을 구축할 계획을 가지고 있습니다. 더 많은 GPU간의 연결을 도모하는 것이죠. 실제로 Broadcom은 Jericho 기반 시스템을 통해 30,000개의 GPU를 연결할 수 있다고 설명하고 있고, Nvidia는 8,192개의 GPU를 연결하는 SuperPod 개념을 제안하고 있습니다. 그리고 긴 거리를 연결하기 위해서는 Optical Communication이 필수입니다. 따라서 Backend Network의 규모가 커질수록, 기존에는 없던 시장이기에 Optical Component를 제공하는 기업들에게 폭발적인 성장의 기회가 발생할 수 있다고 생각합니다.


Backend Network를 구성하는 다른 요소들은 Frontend Network의 구성과 거의 동일하기에, 추가적인 Implication은 Frontend의 그것과 동일합니다. 예를 들어 Frontend Network의 Implication 1과 같이, 앞으로 Infiniband, Feature-rich Ethernet 모두 Bandwidth를 늘리는 각축에 돌입할 가능성이 높습니다.
더하여, 앞서 언급했던 것과 같이 CXL이 이 Backend Network에 연결될 수 있다면, 그래서 GPU가 넓은 Bandwidth로 데이터를 교환할 수 있게 된다면 CXL 메모리 Pool은 무한정 확장될 수 있을 것이라고 생각합니다. 이는 소프트웨어만 준비한다면 이미 갖추어져 있는 시스템에도 적용이 가능하기에 (Rack만 하나 더 추가하면 됩니다.) CXL이 Main 프로토콜로 자리잡는 것보다 훨씬 높은 Scalabaility와 성장성을 가져갈 수 있다고 생각합니다.
Summary
Datacenter는 Package - Rack - Pod - Datacenter로 이루어지는 계층적인 구조를 가지고 있으며, 향후 점점 규모가 커질 AI Model과 Data의 양을 감당하기 위해 더 큰 시스템을 효과적으로 연결하는 네트워크 반도체에 대한 관심이 증가하고 있음. 각 계층에서는 아래와 같은 주요 변화가 발생하는 중.
(이번 포스팅에서 다루지 않음) Package level:
여러 개의 Die를 하나의 Package에 실장하는 Advanced Packaging 기술이 점차 강조되는 중
Die-Die 간 통신을 통합할 UCIe 표준이 등장하며 유관 supply chain의 성장 기대
Rack level → 중요한 Implication을 얻었으나 적합한 기업은 찾지 못함.
PCIe 표준이 점차 설 자리를 잃어가고 있으며, NVLink / Infinity Fabric과 같은 Proprietary Network가 전선을 확대하고 있음
PCIe의 물리 인터페이스를 활용하는 CXL에게도 Rack 내에서는 제한적인 기회가 주어질 것으로 보임. 시장 규모를 확대하기 위해서는 Rack 바깥에 거대한 Memory Pool을 만들고, 이를 Backend Network에 연결하는 아이디어 제안. 이를 구현하기 위해서는 높은 Bandwidth를 가지는 Infiniband/Ethernet - PCIe 변환 Switch 필요. → 아직까지 Player 찾지 못함
무한정 늘어날 수 있는 CXL의 특성을 고려할 때, Elementwise 연산이 가능한 CXL 기반의 PIM 엔진은 Hyperscaler에게 엄청난 인기몰이를 할 것이라고 생각됨. → Samsung, 국내 주요 AI Accelerator의 움직임을 살펴보아야 함
NIC과 DPU의 중요성이 증가하고 있으며, 실제로 Rack 내 GPU당 NIC/DPU 개수는 증가하고 있음. Application specific한 NIC/DPU가 증가할 것이라고 생각하며, 이에 따라 SKU의 숫자가 늘어난 파편화된 시장이 될 것이라고 판단됨
Pod-to-Datacenter level → Broadcom/Nvidia의 변화를 살펴야 함, Fabrinet에 투자 기회가 있을 것
Frontend Network = 스토리지 Pod과 Computing Pod을 연결하는, 데이터 전송에 특화된 Network
Switch IC의 Bandwidth가 증가할수록 Datacenter의 규모를 키우는 데 필요한 비용이 비약적으로 감소. 이에 따라 앞으로 Switch IC는 높은 Bandwidth를 제공할 수 있는 소수 사업자들의 과점 시장이 될 것 → (Top) Broadcom, Nvidia // (Follower) Marvell, Cisco, Intel
Datacenter 규모 증가에 따라 필요한 Optical component의 Q 증가 중. P 감소를 위해 Transceiver의 Digital Signal Processor(DSP)를 제외하는 Linear Direct Drive 기술이 도입되고 있음. 이에 따라 Switch IC와 Transceiver의 Driver / Transimpedence Amplifier의 Interoperability 중요성 증가 → Broadcom - Macom - Arista Networks 협력 구도, Nvidia
Transceiver 당 Bandwidth가 증가하면서 Optical Channel 당 데이터 전송량, Optical Channel의 개수가 모두 증가하고 있는 상황. 이를 생산하기 위해서는 매우 뛰어난 Optical component (Laser, Photodiode, Antireflection coating) 제조 역량, High-precision Assembly 역량 필요. → Fabrinet (Nvidia, Cisco의 Transceiver 위탁 생산) // Broadcom-Arista Neworks의 Transceiver 위탁 생산 중인 기업을 찾아야 경쟁력에 대한 정확한 평가 가능
Loss 최소화를 위한 Co-packaged Optics의 등장. Advanced Packaging 다음 포스팅에서 상세히 다룰 계획
Backend Network = GPU-GPU 등 Accelerator간의 병렬/분산 컴퓨팅을 돕는, 컴퓨팅에 특화된 Network
Infiniband의 운동장이었으나, 최근 Ethernet이 빠르게 시장에 침투하고 있음. 핵심적인 이유는 Hyperscaler들이 Infiniband의 최강자인 Nvidia를 견제하기 위함도 있을 것이라고 판단. Nvidia는 In-network computing으로, Broadcom은 뛰어난 network control 기능으로 경쟁하는 중. → (Infiniband) Nvidia, (Ethernet) Broadcom // 추가로, Ethernet 시장의 유의한 기업들에게 새로운 성장 시장 개척의 기회 발생
Backend Network 역시 Frontend와 마찬가지로 Pod-to-Pod 영역으로 확대되며 Optical Component Q에 높은 성장성을 제공할 것.