
Tech | AI Chip (2) TPU
TPU가 딥러닝 연산에서 효율적인 이유는 무엇일까?

첫 번째 포스팅에서 CPU가 어떤 기본 구조를 가지고 있는지 살펴보았고, 왜 딥러닝에서 활용되기 어려운지 살펴보았습니다.
이번 포스팅에서는 Google의 Tensor Processing Unit, TPU를 살펴봅니다. TPU는 “Systolic Array”라는 기본 구조를 차용하고 있는데요. Systolic Array는 하나의 데이터를 여러 번 활용하는 “데이터 재사용(Data reuse)”에 특화된 구조입니다.
이제는 많은 분들이 알고 계시겠지만, 메모리에서 데이터를 불러오는 작업에는 굉장히 긴 시간이 필요합니다. 따라서 Systolic Array는 하나의 데이터를 여러번 활용하게 되는 행렬곱(Matrix Multiplication) 연산에서 아주 뛰어난 성능을 보이게 됩니다. (정확히는 행렬곱을 비롯한 다수의 행렬 연산에서 뛰어난 성능을 가집니다.) 그런 이유로 Systolic Array 구조는 AI Chip 설계의 한 가이드라인이 되고 있습니다.
이번 포스팅에서는 TPU의 기본 구조부터 시작해 TPU의 발전 과정에서 어떤 중요 기술들이 추가되었는지 천천히 짚어보도록 하겠습니다.
참고
Google은 2-3년 동안 구글 실제 서비스에서 TPU를 활용한 뒤 다음 세대 TPU를 적용할 시점에 이전 세대의 TPU에 대한 retrospective paper를 출판한다고 직접 언급하였습니다. 따라서 가장 최신의 TPU에 관한 정보는 접근할 수 없었음을 미리 말씀 드립니다.
TPU v1, 2015
첫 번째 TPU는 2015년부터 사용되었고, Google은 2017년에 논문을 통해 처음으로 그 구조를 발표합니다. TPU v1은 추론에 활용되는 AI Chip이었습니다. CPU와 비교해 핵심적인 변화 지점은 다음과 같습니다.
TPU v1 논문
명령어 제어 로직의 삭제와 간소화된 ISA
TPU는 CPU가 전달하는 명령어를 받아 연산을 수행합니다. 논문에서도 TPU는 CPU의 Coprocessor 개념으로 설계했음을 밝힙니다.
“To reduce the risk of delaying deployment, Google engineers designed the TPU to be a coprocessor on the I/O bus rather than be tightly integrated with a CPU, allowing it to plug into existing servers just as a GPU does.”
따라서 CPU에서 우리가 살펴보았던 것처럼 명령어 제어를 위한 Fetch unit, Decoding unit, Reorder Buffer, Reservation Station 등 대부분의 구조들이 불필요해집니다. 덕분에 TPU die 면적 대부분은 연산 장치와 이 장치에 공급할 데이터를 임시로 저장하는 임시 저장소(Buffer)로 이루어지게 됩니다.
더하여 TPU는 꼭 필요한 연산만을 수행하는 아주 간소한 ISA를 가집니다. 논문에서는 약 12개 정도의 명령어로 ISA가 이루어져 있다고 언급합니다. x86 ISA가 5,000장을 넘는 것과 비교하면 무척이나 간단합니다.
“It has about a dozen instructions overall, but these five are the key ones:”
ISA가 간단하다는 것은 여러 의미를 가집니다.
소프트웨어를 만들기 굉장히 쉬워집니다. 예를 들어 TPU는 “라면 끓여줘”를 한번에 이해할 수 있습니다.
하지만 소프트웨어를 만드는 과정에서 유연성은 떨어지게 됩니다. 예를 들어 TPU는 “라면 끓일 때 계란 넣어줘” 혹은 (라면과 비슷한) “비빔면 만들어줘” 라는 연산을 수행하지 못합니다.
다르게 이야기하면 제한적인 연산만을 수행할 수 있다는 것이고, 또 다르게 해석하면 그 제한적인 연산을 누구보다 잘 할수 있는 하드웨어라는 것입니다. 바로 Systolic Array라는 독특한 구조 때문입니다.
Systolic Array
Systolic Array는 위 그림과 같은 구조를 가집니다.
Systolic Array는 굉장히 많은 연산 장치를 배열해둔 구조입니다. 따라서 배열된 연산 장치의 수가 많을수록 하나의 연산 장치 - 혹은 Cell은 넓은 면적을 차지할 수 없으며, 제한적인 연산 1~2개만을 수행할 수 있도록 설계됩니다. 실제로 TPU v1의 Cell은 Fused Muliply-Add (FMA) 연산만을 수행하도록 설계되었습니다.
위 그림에서는 2x2 Systolic Array가 2x2 행렬곱 연산을 수행하는 방식을 설명하고 있습니다. 이번 포스팅에서는 구체적인 수행 방식은 다루지 않겠습니다. 다만, 여기에서 초록색으로 칠해진 b11에 주목해보겠습니다.
Cycle 0일 때에는 Systolic Array 밖에서 입력을 기다리고 있습니다. Cycle 1에는 Systolic Array의 Unit (1,1)에 입력되어 a11과 FMA 연산을 수행합니다. Cycle 2에는 Systolic Array의 Unit (1,2)에 입력되어 a12와 FMA 연산을 수행합니다.
이처럼 b11은 Systolic Array에 입력된 후 a11, a12를 만나 총 두번의 FMA 연산에 참가했습니다. 조금 더 일반적으로, n*n Systolic Array에 입력되는 b11은 n번의 FMA 연산에 참가할 것이라고 짐작해볼 수 있습니다. 이처럼 Systolic Array에 입력된 데이터는 여러 번 연산에 참여하게 되면서, 메모리 호출 과정을 최소화합니다.
행렬곱을 수행하기 위한 기본 방식은 위의 2x2 Systolic Array 와 다르지 않지만, TPU는 256x256 크기의 systolic array를 차용합니다. 무려 65,636개의 cell을 갖추고 있는 것인데요. 따라서 각각의 cell에게 허용된 면적은 상당히 제한적이었습니다. 이에 따라 TPU의 cell은 8bit짜리 정수 (int8) 데이터를 입력받아 FMA 연산을 수행합니다.
부동 소수점 - Floating Point 연산 수행에 필요한 연산 장치는 정수 연산 장치보다 훨씬 복잡합니다. (뒤이어 업데이트할 GPU 포스팅에서 상세히 다룹니다.) 만약 Systolic Array에 Floating Point Unit을 추가했다면 TPU는 256x256보다 작은 크기의 (예를 들어, 64x64) Systolic array만을 구현할 수 있었을 것입니다.
Google은 추론 과정에서는 상대적으로 Precision, 즉 정밀도가 중요하지 않다는 판단 하에 과감하게 int8 FMA 연산만을 Systolic Array에 구현합니다
저는 이러한 전략이 주효하게 활용될 수 있던 가장 큰 이유는 TPU가 추론을 통해 고객에게 전달하고자 하는 서비스가 ‘검색 엔진’이었기 때문이라고 생각합니다. 검색 엔진은 상대적으로 정밀도가 떨어져도 서비스 퀄리티에 대한 불만족이 적은 영역이기 때문입니다. 만약 ‘자율 주행’ 영역에서 정밀도를 포기했다면 어마어마한 참사가 일어났을 가능성이 높습니다.
TPU Die
Systolic Array만 덩그러니 놓여져 있으면 아무런 연산도 수행할 수 없습니다. 명령어도 받아야 하고, 그 명령어를 수행할 대상인 데이터도 전달해야 합니다. Systolic array를 포함한 TPU는 아래와 같은 구조로 이루어져 있습니다.

이번 섹션에서는 제가 나름대로 해석한, 조금 더 간소화된 TPU의 구조를 활용해 데이터가 어떻게 TPU로 들어와서 연산을 수행하게 되는지 단계별로 설명합니다.

먼저 CPU에서 준비한 명령어를 Host interface로 받아옵니다. 여기서는 Host interface라고 표현되어 있지만 다르게는 “Instruction Buffer”의 역할을 합니다. 명령어들을 임시로 저장해두는 저장고라고 보면 됩니다.

Unified Buffer에는 Neural Network의 Local activation을 저장합니다. 시작 단계에서는 CPU가 전달한 명령어에 따라 추론에 활용할 입력 데이터를 메인 메모리 DRAM에서 가져옵니다.

마찬가지로 Matrix Muliplication에 참여할 Weight를 메인 메모리에서 Weight Buffer로 전달합니다. 이제 Systolic Array에 데이터를 입력할 준비가 완료되었습니다.
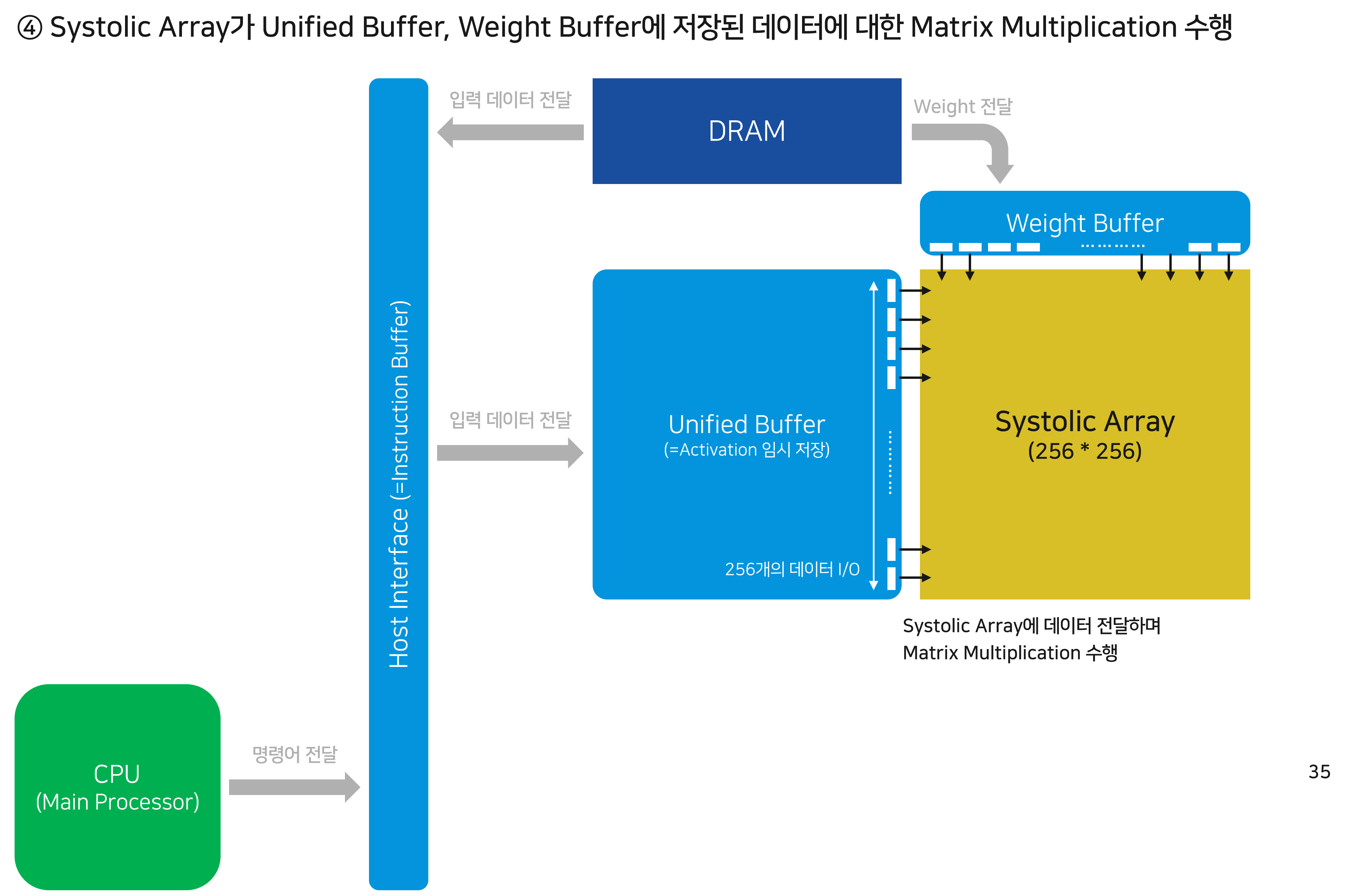
준비된 Unified Buffer의 데이터와 Weight 데이터를 Systolic Array에 흘려보내기 시작합니다. 위에서 살펴본 바와 같이 각각의 Cell에서 FMA 연산을 수행하여 행렬곱 연산을 진행합니다.
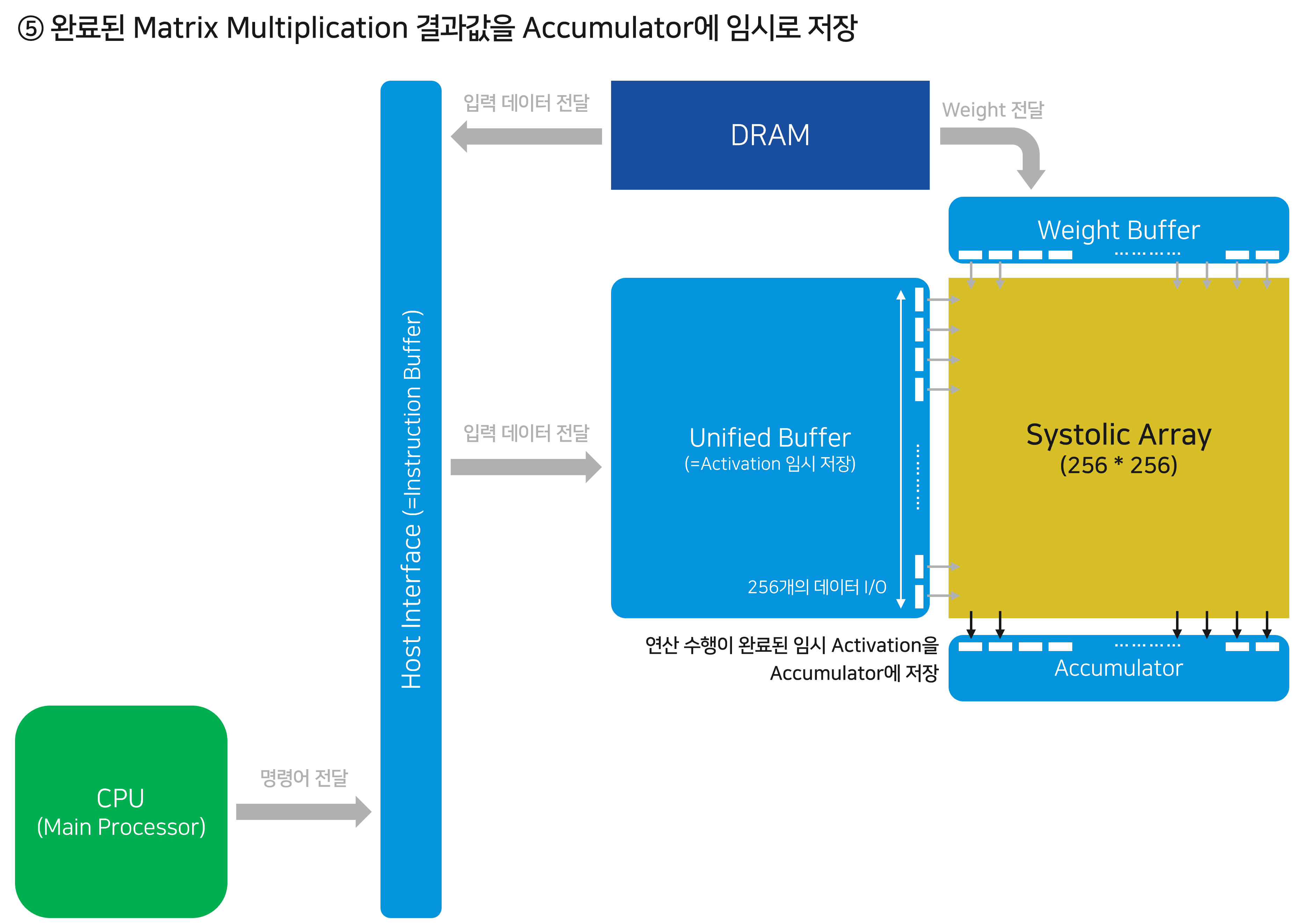
Matrix Multiplication 연산이 완료되면, 이 데이터를 Accumulator라고 불리는 작은 저장소에 전달합니다.

Accumulator에 전달된 값들은 비선형 함수인 Activation을 통과하고, Normalize/Pooling 연산을 수행합니다. 이와 같은 데이터 연산과 흐름은 Neural Network의 Forward Propagation 과 완벽히 동일합니다. “알고리즘을 하드웨어에 구현”했다고 표현할 수 있겠습니다.
참고: 딥러닝의 Forward Propagation에 대해 잘 정리된 글을 공유합니다.

이렇게 계산된 Local activation은 다시 Unified Buffer로 이동해 다음 연산을 진행할 차례를 기다립니다.
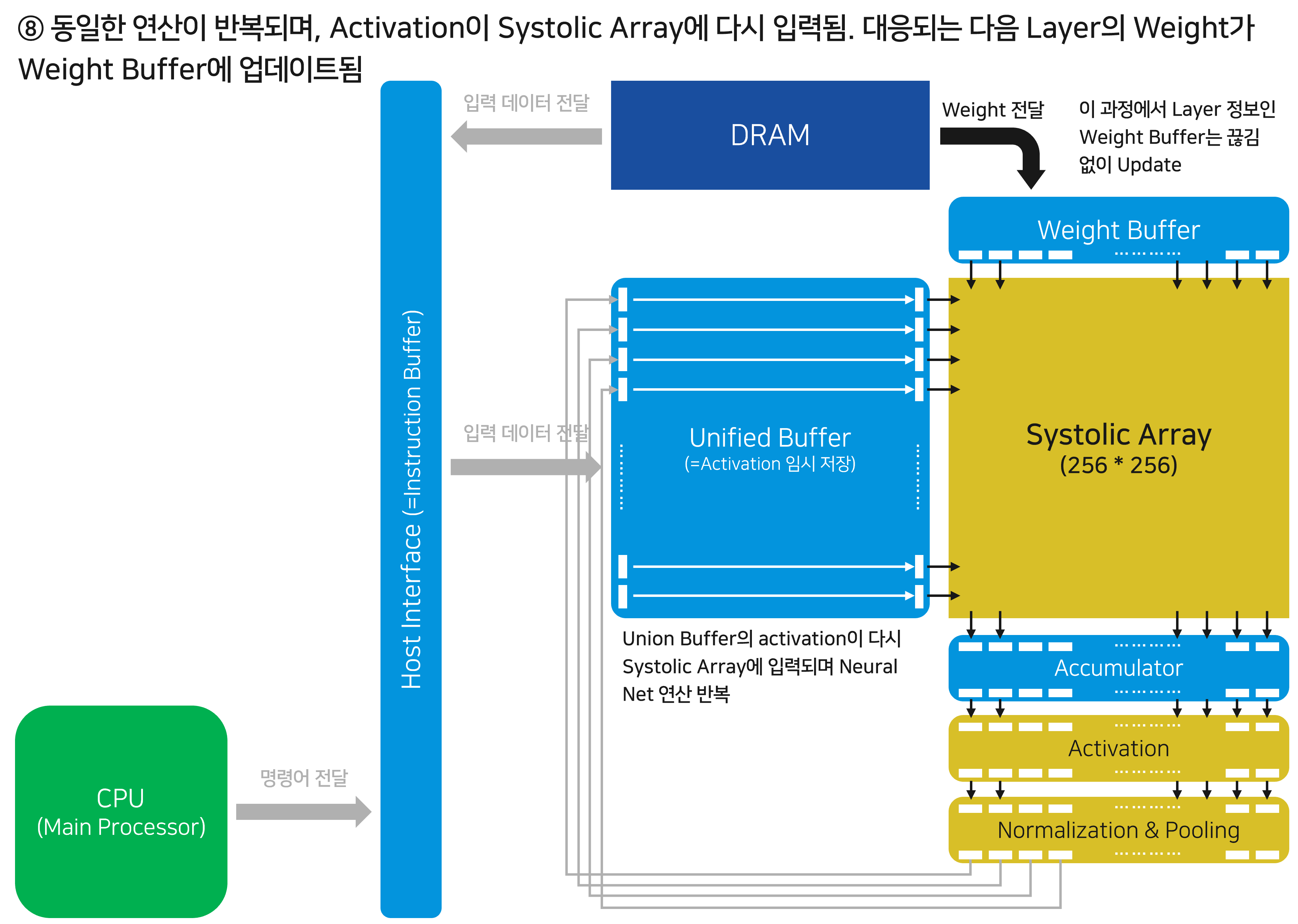
Unified Buffer에 저장되었던 Local Activation이 Systolic Array에 다시 입력될 순서가 되었을 때, 대응되는 Weight가 Weight Buffer에 업데이트 됩니다. 준비된 데이터를 Systolic Array에 입력해 행렬곱 연산을 다시 수행하게 됩니다. 4번~8번의 과정을 반복합니다.
결과적으로 한 번 입력된 데이터는 Systolic Array를 여러 번 거치며 재사용됩니다. 이러한 교환 방식 덕분에, TPU에서는 한 차례 데이터를 입력하면 이론상 Inference가 완료될 때까지 메모리와 별도의 데이터 교환을 수행하지 않을 수 있습니다.

추론 과정이 완료되었다면, Unified Buffer에 저장된 최종 결과 데이터를 다시 Host Interface에 전달합니다. Host Interface는 이를 다시 CPU에게 전달하거나, 혹은 메인 메모리인 DRAM에 저장할 수도 있습니다.
지금까지 TPU v1에서 데이터가 어떻게 이동하는지 천천히 살펴보았는데요. 제가 생각하기에 TPU v1을 구성하는 많은 Building Block들의 공통된 특성은 “한 종류의 데이터”만을 다루고, “한 방향으로만 데이터를 전달”한다는 것입니다. 예를 들어 Weight Buffer는 DRAM으로부터 Weight를 전달받아 Systolic Array에 전달하는데요. Buffer에 저장된 값을 다시 DRAM으로 보내거나, Weight가 아닌 다른 값을 전달 받는 경우가 없습니다. 무척이나 단순한 작동 방식과 Systolic Array라는 구조 덕분에 TPU v1은 행렬곱 연산을 포함한 딥러닝 연산에 아주 뛰어난 성능을 보입니다.
Decoupled Access and Execution 구조

위 그림과 같이 TPU의 메모리 접근 경로와 연산 수행 경로는 서로 나누어져 있습니다. 메모리 접근을 위해 연산 장치를 멈추지 않아도 되고, 연산을 하기 위해 메모리 접근을 멈추지 않아도 된다는 의미입니다. 반대로 CPU의 경우 메모리 접근과 연산 수행이 동일한 경로를 공유하기 때문에 동시에 두 작업을 수행할 수 없습니다.
이처럼 메모리 접근과 연산 수행이 독립적으로 수행될 수 있는 컴퓨팅 구조를 “Decoupled Access and Execution(DAE)” 구조라고 부릅니다. 관련해서 Onur Mutlu 교수님의 강의를 공유합니다. (정말 대단한 교수님이십니다. 제가 지금까지 들었던 모든 강의 중 최고의 강의라고 해도 손색이 없습니다. 강추합니다.)
메모리 접근과 연산이 분리된 덕분에 Systolic Array에 끊김 없이 데이터를 스트리밍해줄 수 있게 됩니다. 조금 가혹할 수 있지만 Systolic Array에게 쉴 시간을 주지 않을 수 있게 되고, 하드웨어 가동률을 극대화할 수 있게 됩니다.
DAE 구조는 NVIDIA Hopper 아키텍처의 “Tensor Memory Accelerator”에서도 유사하게 적용되었습니다. 메모리 접근을 위한 주소 계산을 TMA에 위탁하여 메모리 접근과 연산 수행을 위한 경로를 나누었는데요. 상대적으로 메모리 접근에 필요한 연산은 간단한 편이므로, 작은 면적을 할애해 DAE 구조를 구현하는 것이 하나의 트렌드가 되어가는 모양새입니다. 관련해서는 다음 GPU 포스팅에서 상세히 다루도록 하겠습니다.
여담으로, Systolic Array, DAE 구조는 1980년대에 제안되었던 개념입니다. Google은 은근히 자신들이 이런 빈티지한 감성(?)으로 뛰어난 프로세서를 만들었음을 자랑합니다.
“For the TPU, three important architectural features date back to the early 1980s: systolic arrays, decoupled-access/execute, and CISC instructions….History aware architects could have a competitive edge…” (이번 포스팅에서는 CISC instruction 구조까지는 다루지 않고 있습니다.)
정리
TPU v1은 추론을 위해 만들어졌습니다.
Systolic Array라는 구조를 활용해 데이터 재사용 빈도를 높입니다. 거기어 더해 Unified Buffer, Systolic Array, Accumulator가 서로 데이터를 순환시키는 구조를 만들어 메모리와의 데이터 교환을 최소화합니다.
하드웨어 구조가 소프트웨어의 작동 방식을 그대로 구현했기 때문에, TPU v1의 ISA는 무척 간단하고 프로그래밍하기 쉽습니다.
TPU v2
2015년 이후 몇 차례의 딥러닝 붐이 일어납니다. Batch Normalization, Residual Network가 기존 학습 과정에서 발생했던 중요한 문제를 간단한 아이디어로 해결해내면서, 인간을 뛰어넘는 인공지능이 속출했습니다. 화룡점정으로 2016년에는 알파고가 세상을 뒤흔듭니다. 앞으로도 수많은 회사들이 새로운 인공지능 모델을 만들고자 노력할 것이라는 관점에서, Google은 추론을 넘어 학습을 목적으로 한 TPU v2를 개발합니다.
Google의 두 번째 TPU는 2017년부터 활용되었고, 2020년이 되어서야 논문을 통해 세부적인 구조를 발표합니다. 추론 목적의 칩에서 학습 목적의 칩으로 진화하며 컴퓨팅 구조 상에서 많은 변화가 있었는데요. 지금부터 자세히 살펴보겠습니다.
TPU v2~v3 논문
A domain-specific supercomputer for training deep neural networks
The Design Process for Google's Training Chips: TPUv2 and TPUv3
학습과 추론의 차이에서 오는 변화 지점
2020년 구글의 논문에서는 아래와 같은 학습과 추론의 차이점을 언급합니다.
Harder Parallelization: 추론은 각각의 입력 데이터에 의한 결과가 독립적이지만, 학습은 수백만 개의 데이터가 하나의 모델을 만들기 때문에 데이터 1개에 대한 연산이 서로 독립적이지 않습니다. 병렬적으로 수행되는 학습 데이터의 수에 따라 최종 모델이 달라질 수 있습니다.
More Computation: 추론은 Forward Propagation을 수행하면 끝이지만, 학습은 Backward Propagation까지 수행해야 합니다.
More Memory: Back Propagation 과정에서 학습 이전 모델의 weight를 포함해 임시로 저장해야 하는 데이터의 양이 많아집니다.
More Programmability: 학습을 위한 최적화 알고리즘, Neural Net 모델의 구조는 계속해서 바뀌기 때문에 ISA 수준에서 유연성을 제공해야 합니다.
Wider (More precise) data: 추론 과정에서는 약간의 오류가 큰 문제를 야기하지 않습니다. 이에 따라 INT8 데이터를 활용했습니다. 하지만 학습 과정에서는 약간의 차이로 인해 학습된 모델의 성능 차이가 확연히 바뀔 수 있습니다. 예를 들어 아주 작은 값을 INT8으로 근사시키면, 많은 weight 값이 0으로 표현되어 학습 자체가 멈출 수도 있습니다. 이에 따라 아주 작은 차이도 반영할 수 있는 Floating Point (FP) 연산이 필요합니다.
그리고 이런 변화 지점을 만족시키기 위해 아래와 같은 기술을 적용합니다.
변화 1. 복잡해진 Vector Processing Unit과 VLIW의 차용
구글은 더 많아진 Memory의 필요성과 적합한 수준의 Programmability를 제공하기 위해 기존에 명확하게 정의되어 있던 Dataflow를 조금 더 유연하게 바꾸기 시작합니다.
(Remind) TPU v1에서는 대부분의 Building Block이 “한 종류의 데이터”만을 다루고, “한 방향으로만 데이터를 전달”한다고 설명했습니다. 이렇게 결정된 Dataflow를 가지는 하드웨어는 다양한 구조의 프로그램을 수행하기 어렵습니다.
특히 Systolic Array에 데이터를 입력할 때 별도의 연산을 수행할 수 없고, Accumulation된 값들을 Unified Buffer에 저장할 때에도 Activation, Pooling 이외의 연산을 수행할 수 없습니다. 이에 따라 TPU v1은 학습에서 필수적인 Batch Normalization, Residual Connection을 수행할 수 없습니다.
이에 따라 TPU v1을 시작점으로 삼아 단점을 개선하며 학습에도 활용할 수 있는 프로세서로 탈바꿈하는 과정을 거칩니다. 이를 상세히 설명하자면 다음과 같습니다:

TPU v1에서는 유사한 맥락, 동일한 구조의 데이터를 저장하는 Accumulator와 Unified Buffer가 분리되어 있었습니다. 이를 하나로 합쳐도 연산 수행에 문제가 되지 않으므로, 이를 통합하고 “Vector Memory”라고 명명합니다.
그리고 기존에는 단순히 Nonlinear activation과 Normalization/Pooling을 수행했던 Activation Pipeline에 조금씩 다른 연산을 추가하며 “Vector Unit”이라는 이름으로 표현하기 시작합니다. Vector Unit은 Matrix multiplication이 아닌 Vector 연산을 수행합니다.
Weight buffer 역시 Vector Memory와 유사한 맥락, 동일한 구조의 데이터를 저장합니다. 이에 따라 Weight buffer도 Vector Memory에 통합합니다.
TPU v1에서 Unified Buffer와 Accumulator는 Systolic Array에 직접 데이터를 전달했습니다. 하지만 TPU v2에서는 Systolic Array에 대한 데이터 입/출력 과정에서 모두 Vector Unit을 거칩니다. Vector Unit은 Batch Normalization, Residual Connection을 포함한 학습 과정에서 필요한 데이터 처리 프로세스를 수행합니다. TPU v1과 비교할 때 가장 큰 변화라고 할 수 있습니다.
TPU v1에서와 달리 TPU v2의 Building Block은 다양한 종류의 데이터를 다양한 방향으로 전달하기 시작합니다. 예를 들어 Vector Memory에는 입력 데이터, Weight, Activation 값이 저장되고, Vector Unit에 데이터를 전달하기도 하지만 Vector Unit으로부터 데이터를 전달받기도 합니다. 이에 따라 어떤 데이터를 어떤 방향으로 보낼 것인지에 대해 Vector Memory에게 알려줘야 합니다. 이처럼, TPU v2에서는 복잡해진 하드웨어를 매끄럽게 구동시키기 위해 제어 장치를 추가합니다.
Vector Processing Unit의 작동 구조
Vector Memory와 Vector Unit을 합쳐 Vector Processing Unit이라고 명명합니다. Vector Memory는 총 128개의 Lane으로 나누어져 있고, 각각의 Lane의 Vector Unit의 8개 SubLane과 연결되어 있습니다. 지금부터 TPU v1에서 살펴보았던 방식대로 Dataflow를 천천히 살펴보겠습니다.
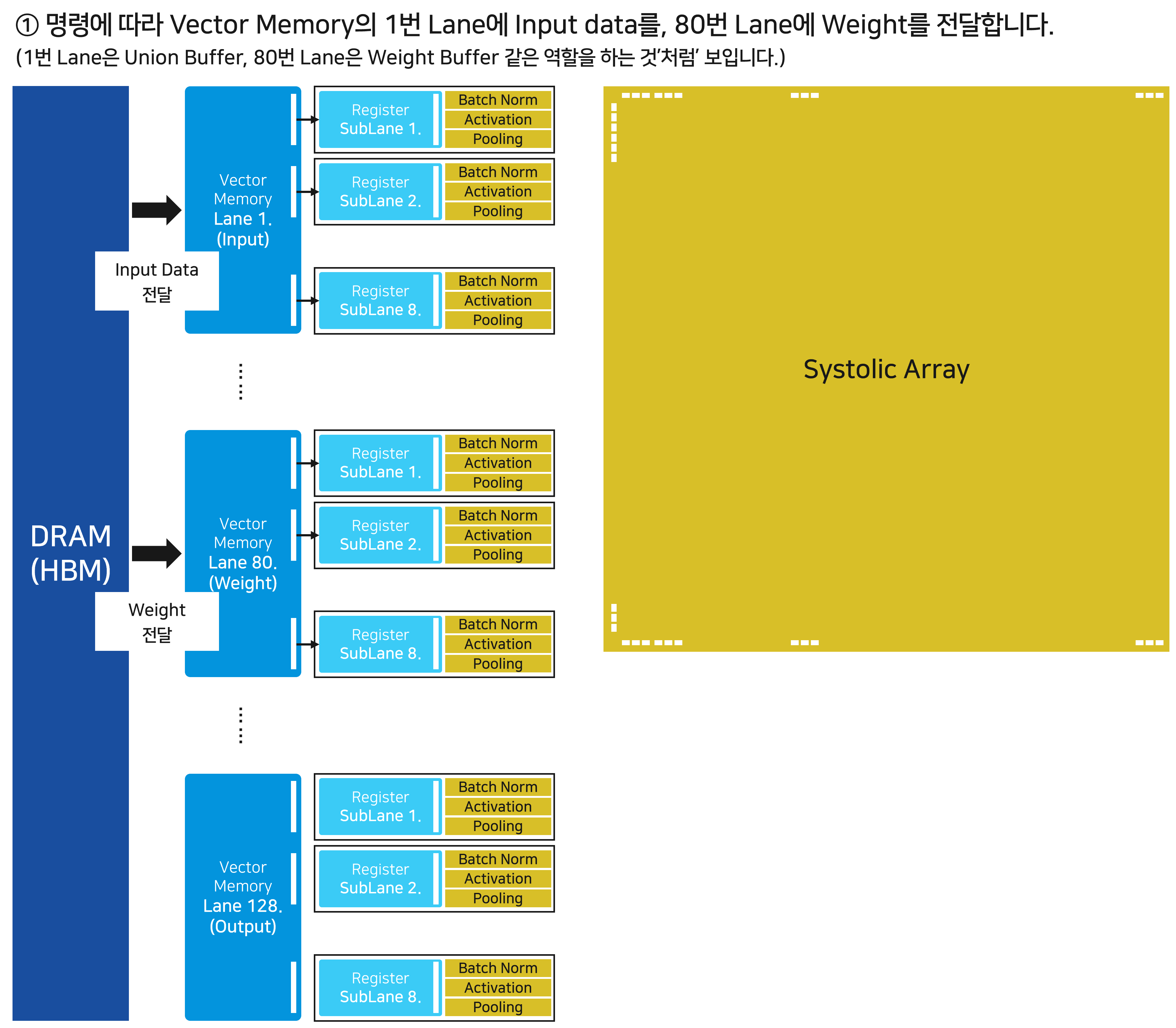
먼저 Vector Memory는 메모리로부터 입력 데이터와 Weight를 전달받습니다. v1에서는 각각 Unified Buffer와 Weight Buffer에 전달했지만, 이제는 Vector Memory의 구분된 Lane으로 데이터가 전달됩니다.
제어 신호의 필요성이 점차 강조됩니다. 가령, 제어 장치는 (Vector Memory의 Lane 넘버, 데이터의 종류, 입/출력 여부) 등을 포함한 제어 신호를 DRAM과 Vector Memory에 명확히 전달해야만 합니다.
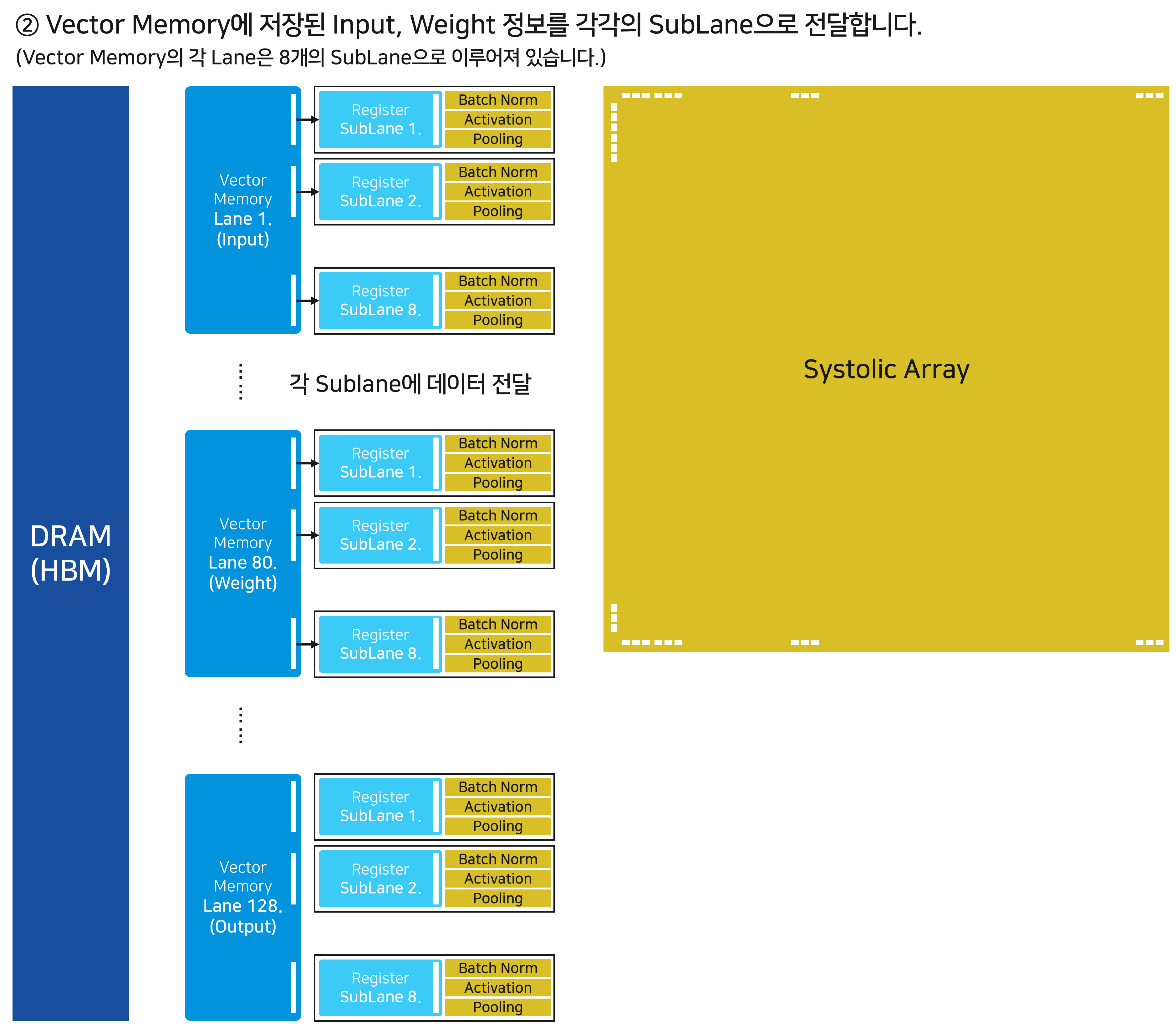
이제 Vector Memory에 위치한 각각의 데이터를 Vector Unit의 SubLane으로 전달합니다.

SubLane의 레지스터는 명령을 전달 받아 데이터 처리를 진행합니다. 여기서 제어 장치는 Batch Normalization이라는 하나의 명령어를 수십, 수백 개의 SubLane에 전달하게 됩니다. 전달 받은 수십, 수백 개의 SubLane은 동시에 Batch Normalization을 수행합니다.
Key Point 1: 하나의 명령어를 여러 개의 SubLane이 수행하는 이 모습은 GPU의 SIMT 구조를 닮았습니다. (다음 포스팅에서 GPU의 구조에 대해 자세히 다루겠습니다.)
Key Point 2: Vector Memory와 Systolic Array 사이에 Vector Unit을 배치하는 것을 통해, Batch Normalization과 같이 입력 데이터를 Systolic Array에 전달하기 전에 꼭 수행해야 하는 데이터 처리 작업을 수행할 수 있게 됩니다.

위 과정을 통해 Systolic Array에 입력할 입력 데이터와 Weight가 준비되었습니다. 이제 준비된 데이터를 입력해 행렬곱 연산을 수행합니다.

같은 시각, 연산이 완료된 데이터들이 다시 Vector Unit으로 돌아옵니다. 모든 행렬곱 연산의 앞/뒤에는 Vector Unit이 배치되어 있습니다. Vector Unit은 이처럼 데이터 전/후 처리의 핵심 앵커가 됩니다. 개인적으로는 TPU v2에서 가장 중요한 역할을 한다고 생각합니다.
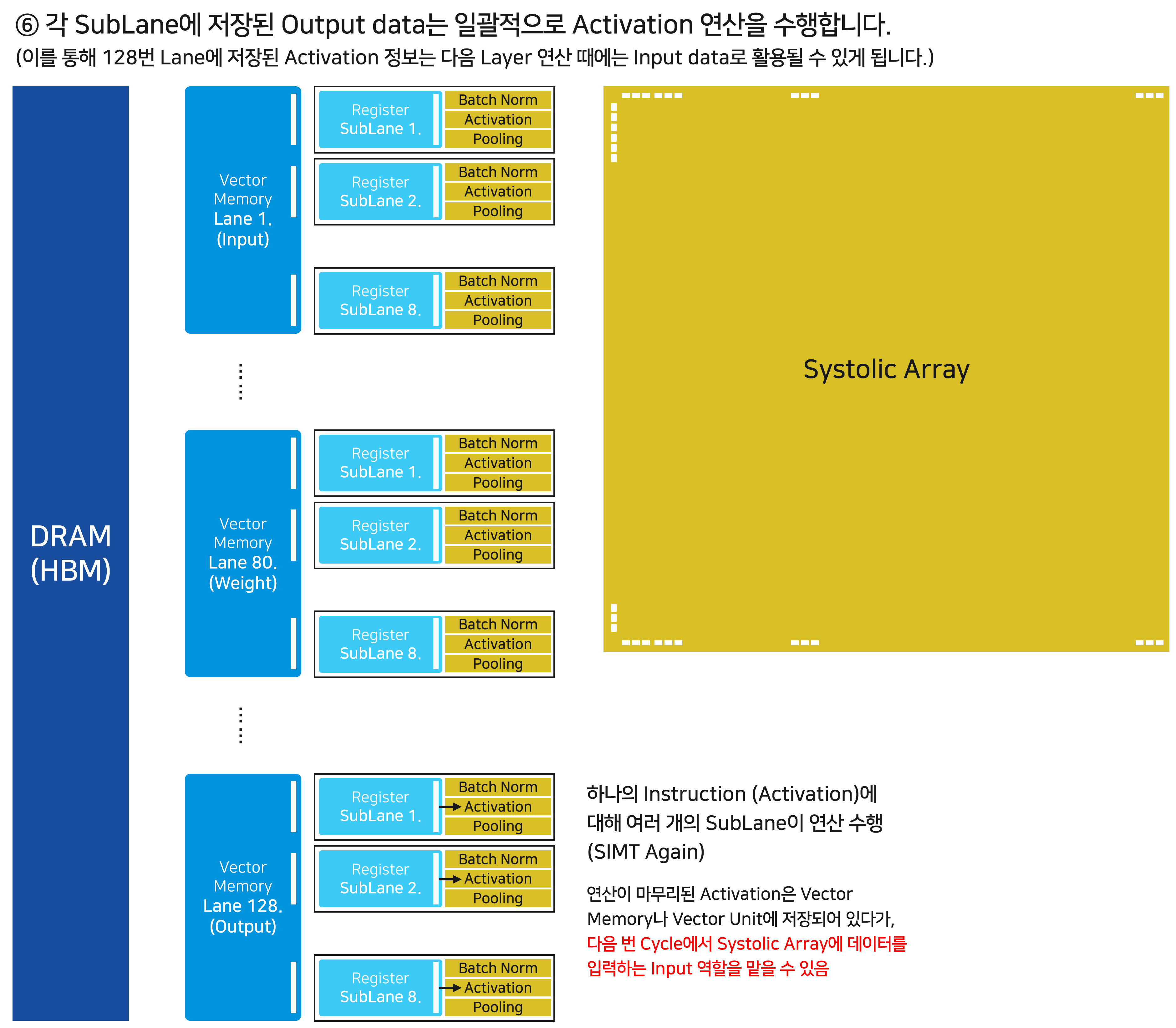
SubLane의 레지스터는 명령을 전달 받아 데이터 처리를 진행합니다. 여기서 제어 장치는 Activation이라는 하나의 명령어를 수십, 수백 개의 SubLane에 전달하게 됩니다. 전달 받은 수십, 수백 개의 SubLane은 동시에 Activation을 수행합니다. (Remind: SIMT 구조)
Activation/Pooling 등의 과정을 거친 데이터는 다음 번 Layer에서는 input으로 활용될 수 있습니다. 이처럼, Vector Memory 각각의 Lane에 속한 데이터는 유동적으로 자신의 역할을 바꾸며 연산을 수행하게 됩니다. 결과적으로 각각의 데이터가 어떤 역할을 하고, 어디로 움직어야 하는지를 똑똑하게 알려줄 제어 장치의 중요성이 강조됩니다.

연산 과정이 완료되었다면 - Forward Propagation과 Backward Propagation을 모두 마무리했다면, 학습된 Weight 값을 메인 메모리에 전달합니다.

1~7번 과정은 모두 독립적인 영역에서 수행되고 있습니다. 각각의 순서를 면밀히 조정해 모든 영역이 멈추지 않도록 해야 전체 디바이스의 가동률을 높일 수 있습니다.
Google은 이를 위해 하나의 매우 긴 명령어에 여러 개의 작동 명령을 저장하는 “Very Large Instruction Word (VLIW)”를 차용합니다. 한 번에 여러 작동 명령을 독립적인 SubLane들에 분배해 쉴 틈을 주지 않는다는 전략입니다.
사실 VLIW 역시 아주 오래전에 제안되었지만 이런저런 이유로 기존 컴퓨팅 시스템에서는 차용되지 않았던 방식입니다. VLIW를 도입함면 ISA가 바뀌고, 소프트웨어가 전반적으로 수정되어야 한다는 점 뿐만 아니라, 처리 속도가 다른 여러 개의 명령어를 효과적으로 제어할 방법이 없다는 문제도 있었습니다.
TPU v2는 그 어려운 일을 해냅니다. 그리고, 아주 뛰어난 컴파일러를 함께 준비합니다. v2 논문에서는 TPU 컴파일러에 대해 꽤나 비중 있게 다루고 있는데요, 이번 포스팅 시리즈에서는 자세히 다루지 않겠습니다.

미시적으로 살펴보았던 TPU v2의 구조를 다시 한 번 거시적으로 표현하고 리마인드하면서, 다음 섹션으로 넘어가보도록 하겠습니다.
변화 2. Smaller Systolic Array
TPU v1은 256x256 Systolic Array를 활용했습니다. TPU v2에서는 25% 크기의 128x128 array를 활용합니다. 그 이유는 다음과 같습니다.
Utilization Rate
TPU v2 논문에서는 256x256 Systolic Array를 활용해 컨볼루션 신경망을 계산할 때의 Utilization은 22~30% 수준이고, 128x128 Systolic Array를 활용할 경우 37~48% 수준으로 증가한다고 언급합니다.
원리적으로 볼 때, Systolic Array의 모든 영역에 데이터를 전달하기 위해서는 꽤 오랜 시간이 필요합니다. NxN Systolic Array의 Cell (N, N)에 데이터가 입력되기 위해서는 최소 N번의 cycle이 지나야 합니다. N번의 Cycle 동안 Cell (N, N)은 아무것도 하지 않는다는 의미입니다. 행렬곱 관점에서 본다면 Utilization rate는 더욱 떨어지게 되는데요. 중요한 점은 Systolic Array의 크기가 커질수록 Utilization은 낮아진다는 점입니다.
Floating Point Unit (FPU) 기술의 부재
Google은 TPU v2에서 Floating Point 16 (FP16) 연산을 지원합니다. Systolic Array 각 cell에 FPU가 추가되어야 합니다. 하지만 GPU 포스팅에서 언급했듯 FPU는 기존의 INT 연산 장치보다 훨씬 높은 복잡도와 넓은 면적을 필요로 합니다. FPU를 효과적으로 집적하지 못한 것도 Systolic Array의 크기를 포기해야 했던 다른 이유일 것으로 생각됩니다.
변화 3. Interconnect: 2D Torus Topology
학습 과정은 엄청난 양의 데이터를 수반합니다. 이에 따라 TPU v2 한 대에서 모든 학습을 수행할 수는 없습니다. 여러 대의 TPU가 동시에 병렬적으로 학습을 진행하는데요. 모든 TPU가 동일한 Weight 값으로 동기화되어 올바른 방향으로 학습을 수행하는 것이 굉장히 중요합니다. 이에 따라 TPU v2에서는 수십 대의 TPU를 Seamless하게 연결해 마치 하나의 거대한 프로세서로 보이게끔 만듭니다.
흥미로운 점은 단순히 Interconnect하는 장비 (데이터 송수신 케이블 등) 뿐만 아니라 이들을 거시적으로 연결하는 구조에 대해 설명하고 있다는 점입니다. “칩 자체의 성능을 넘어 전체 시스템에 대한 고민이 필요하다”는 점을 시사합니다.
네트워크 반도체와 시스템에 대해서는 조만간 별도의 포스팅에서 상세히 다루도록 하겠습니다.
정리
TPU v2는 학습을 위해 설계되었습니다.
학습 과정이 필요로 하는 스펙을 제공하기 위해 Vector Processing Unit (VPU)와 2D Torus Topology를 가지는 TPU-to-TPU Interconnection 기술을 소개합니다.
컴퓨터 구조의 관점에서 볼 때, VPU는 VLIW와 SIMT 구조를 효과적으로 결합한 Multi-Instruction, Multi-Data (MIMD) 구조를 차용하여 행렬 연산의 효율성을 극대화하고 있습니다.
TPU v3
2개의 Systolic array 도입, Floorplanning의 중요성 강조
TPU v3는 v2와 동일한 구조를 차용하지만, Systolic Array를 한 개 더 추가합니다. 앞서 언급한대로, TPU v3는 v2와 함께 그 구조를 발표했습니다.
TPU v2~v3 논문
A domain-specific supercomputer for training deep neural networks
The Design Process for Google's Training Chips: TPUv2 and TPUv3
놀라운 점은, v3는 v2와 동일한 Foundry Technology Node를 활용하면서 Systolic Array라는 커다란 building block을 추가했음에도 전체 면적이 6%밖에 증가하지 않았다는 점입니다. 이에 관해서 구글은 “엔지니어들의 놀라운 Floorplanning 덕분이다”라고 언급하고 있습니다. Floorplanning이란, 설계 과정에서 필요로 하는 로직 컴포넌트를 실제로 평면 위에 어떻게 배치할지 설계하는 과정입니다.
실제로 Google은 TPU v2~v3에 대한 논문을 발표하고 얼마 지나지 않아 Floorplanning 과정에서 강화학습을 적용하는 기술을 발표합니다. 무려 Nature에 소개되었는데요. 이는 앞으로 점점 복잡해지는 칩 설계 과정에서 Floorplanning이 얼마나 중요한 bottleneck 요소로 자리잡을지 알려주는 대목입니다. 그런 이유로 EDA 기업, 디자인 하우스에 기존보다 더 높은 기술적 해자가 자리잡을 가능성이 있다고 생각됩니다.
강화학습을 활용한 Floorplanning 논문
이외에도 v3에서는 몇몇 다른 feature들이 개선되었는데요. Google은 “이미 있던 기술을 잘 활용한 Mid-life kicker”라고 겸손하게 소개합니다. 관련해서 간단하게 다음과 같은 내용들이 있습니다.
Systolic array를 하나 더 추가하면서 한 번의 cycle에 두 배 많은 연산을 처리할 수 있게 되었음.
Pipelining을 최적화하여 Clock cycle을 700MHz에서 940MHz로 증가시킴.
HBM Bumping 기술을 개선시켜 30%의 Bandwidth 개선하고, HBM의 용량을 두배로 늘려 더 큰 데이터셋을 처리할 수 있게 됨.
Interconnect Link의 Bandwidth 30% 개선.
Interconnect Link를 개선시켜 전체 시스템의 최대 개수를 v2기준 256개 chip에서 v3 기준 1024개로 늘리는데 성공.
TPU v4
TPU v4는 2020년부터 활용되었고, 2023년 10월경에 관련 논문을 발표합니다. TPU v4 논문에서 Google이 강조한 내용은 광통신을 활용한 TPU-to-TPU 통신 기술, 이를 기반으로 구축한 3D-Torus Interconnect Topology 두 가지입니다.
단일 TPU는 v2 → v3로 진화하는 과정과 유사하게 기존 기술의 패러다임을 바꾸지 않는 선에서 성능을 확보하는 수준으로 이해하였습니다. 특히, Transformer의 중요성에 대해서는 언급하지만 TPU가 Transformer에서 어떤 역할을 할 수 있는지에 대한 언급이 없어 매우 아쉬웠습니다. 오히려 중요도가 떨어지는 추천 시스템에 필요한 Sparse Core에 대해서만 언급하며 논문을 정리하고 있습니다.
개인적으로는 유의한 구조 변화가 없거나, 핵심 변화 지점은 공유하지 않는 것으로 이해하여 이번 포스팅에서는 TPU v4에 대해 자세히 다루지 않습니다. (다만, 지금까지 제가 공부한 이해 수준에서 중요한 변화 지점을 찾지 못한 것인데요. 다시 한번 세세히 살펴보고 새로운 관점에서 업데이트 해두도록 하겠습니다.)
TPU v3 논문
지금까지 TPU의 발전 과정을 정리해 보았습니다. 개인적으로는 TPU v1에서 직관적인 구조를 제안하고, TPU v2에서 체계적인 구조 변화를 통해 학습용 칩을 만들어내는 과정이 흥미로웠습니다. 다만 최근에는 TPU의 기본 구조인 Systolic Array의 한계점을 지적하는 연구들이 많아지고 있는데요. 개인적으로는 Google이 이러한 한계점을 어떤 방식으로 해결해나갈지 궁금합니다.
다음 포스팅에서는 대 AI 시대의 최종 빌런, GPU를 다룹니다. 의외로 GPU는 2008년 제안된 간단하면서도 강력한 Single Instruction, Multiple Thread (SIMT) 구조를 15년 동안 계속해서 유지하고 있는데요. 왜 SIMT가 AI 시대에 중요한지, 그리고 그러한 간단한 구조를 가지고도 어떻게 지금의 NVIDIA가 거대한 기술적 해자를 가지게 되었는지 설명합니다.
지금까지의 과정을 통해서 컴퓨터가 어떻게 작동하고 데이터는 어떻게 움직이는지 고민했던 만큼, 다른 fabless 기업들이 발표한 논문도 살펴보면서 그들의 구조는 CPU, TPU, GPU와 어떻게 다른지 정리해보도록 하겠습니다. 모두 긴 글 읽어주셔서 감사합니다!