

Tech | AI Chip (1) CPU

이번 포스팅 시리즈에서는 AI 시대를 맞이해 절정의 호황기를 맞이한 시스템 반도체의 작동 원리에 대해 정리합니다. 기존의 산업 리포트나 개별 기업 분석과 달리 이번 포스팅 시리즈는 온전히 ‘기술’ 자체에 집중해서 정리해 보았습니다. 핵심적인 목표는 구독자 여러분들께서 앞으로 쏟아질 수많은 팹리스 기업들을 마주하실 때 “좋은 질문을 던질 수 있도록” 돕는 것입니다.
이번 업데이트에서는 가장 많이 활용되고 있는 CPU, TPU, GPU의 원리와 발전 과정에 대해서 설명합니다. 다음 업데이트에서는 메모리 반도체와 PIM, 네트워크 반도체에 대해 다루고, 최종 업데이트에서는 전체 산업 내 주요 Player들을 다루며 마치려고 합니다.
이미 많은 분들이 알고 계시겠지만, CPU는 딥러닝 연산 처리에 적합한 구조를 갖추고 있지 않다고 평가받습니다. 이번 포스팅에서는 CPU가 어떻게 발전해왔는지를 정리하는 한편, 어떤 부분에서 딥러닝 연산 처리에 적합하지 않은지 설명합니다. 그리고 이를 기반으로 TPU, GPU가 어떻게 CPU의 한계점을 보완했는지에 대해 설명합니다.
Computing 수행의 기본 단위와 Instruction Set Architecture
사실 컴퓨터는 썩 똑똑하지는 않습니다. 맥락을 이해하는 녀석이 아니기 때문에 아주 세세한 것까지 - 우리가 흔히 사회에서 이야기하는 “마이크로 컨트롤”을 필요로 합니다. 간단히 예시를 들어보자면.. “라면 끓여 와”라는 명령을 실제로 수행하기 위해서는 컴퓨터에게 “냄비를 꺼내”, “냄비에 물을 넣어”, “가스레인지에 냄비를 올려둬”, “불을 켜”, …. 등등의 아주 세세하고 단순한 명령으로 쪼개서 전달해야 합니다.
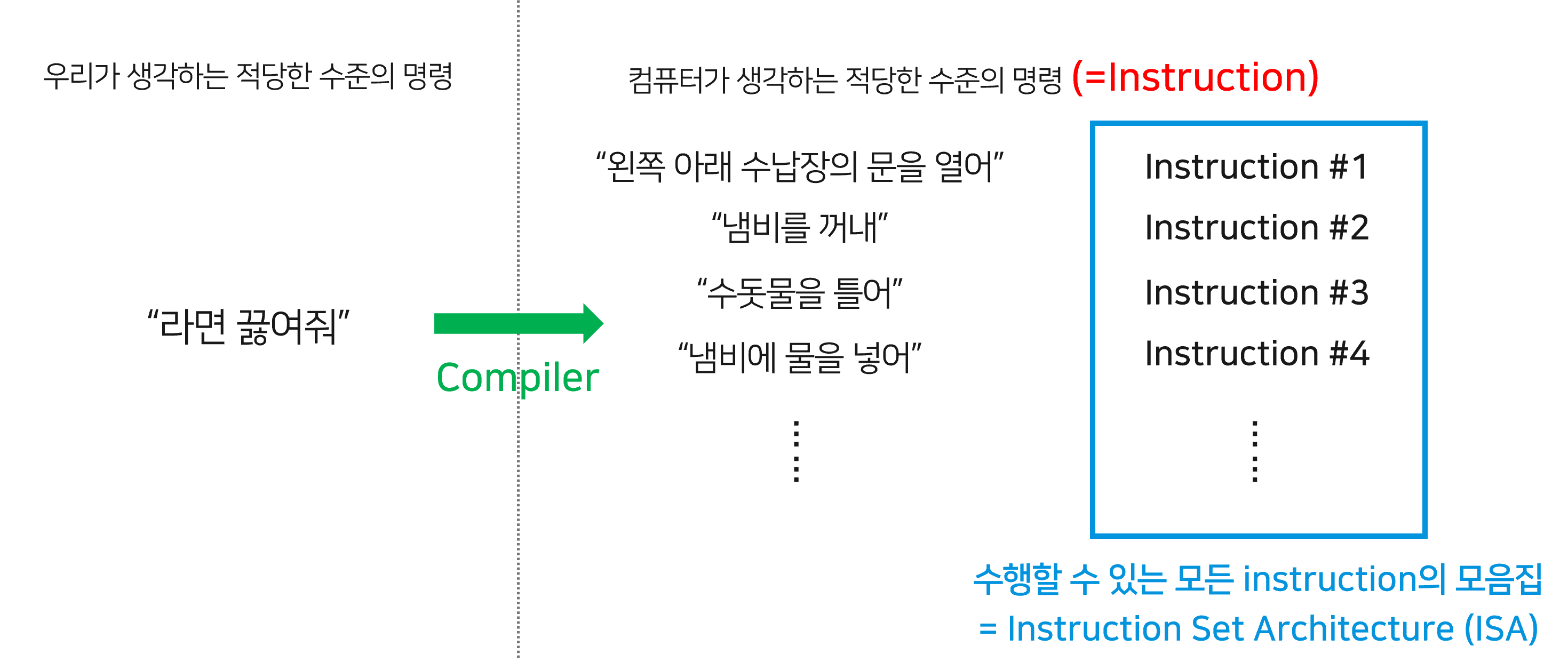
여기서 “냄비를 꺼내”, “냄비에 물을 넣어” 등의 가장 기본적인 명령어들을 우리는 “Instruction”이라고 부릅니다. 그리고, 어떤 한 컴퓨터가 해낼 수 있는 모든 Instruction의 집합을 우리는 “Instruction Set Architecture (ISA)”라고 합니다. 컴퓨터가 이해할 수 있는 일종의 ‘사전’ 이라고 볼 수 있겠습니다. 대표적인 예시가 인텔의 x86 ISA와 ARM ISA입니다. 각각 무려 5,000페이지가 넘는 설명서를 가지고 있습니다.
사실 컴퓨터는 ISA에 속한 명령어 말고는 사실 다른 언어는 이해할 수 없습니다. 그래서 아주 오래전에는 이런 ISA 하나하나를 잘 숙지해서 손으로 한땀한땀 소프트웨어를 만들어야 했습니다. 점차 우리가 이해할 수 있는 수준의 코드를 작성해도 이를 ISA 언어로 해석해주는 “컴파일러”가 발전하면서, 사람들은 보다 쉬운 언어로 프로그램을 만들 수 있게 되었습니다. 컴파일러는 우리가 “라면을 끓여 와”라는 명령어를 입력했을 때, 이를 “냄비를 꺼내”, “수돗물을 틀어”… 의 가장 간단한 명령어들로 바꾸어주는 역할을 합니다.
그리고 하드웨어 개발자들은 위에서 정리한 ISA를 문제없이 잘 수행할 수 있는 회로 구조를 만들어야 합니다. 흔히 우리가 이야기하는 “Kaby Lake, Haswell,…” 등등의 “Microarchitecture”는 위에서 정리한 ISA를 모두 문제없이 수행할 수 있도록 하는 하드웨어 수준에서의 구조를 의미합니다. 놀랍게도 같은 ISA를 구현함에도 불구하고 완전히 다른 Microarchitecture가 나올 수 있습니다. 가령, ‘덧셈’이라는 간단한 Instruction을 수행하는 하드웨어 구조는 수십가지에 이릅니다. 매번 Intel, ARM 등에서 새로운 IP를 개발해내는 것은, ISA를 수행할 수 있는 보다 효율적인 방법을 도출해내는데 성공했기 때문입니다.
여기서 중요한 다른 지점은, ISA를 함부로 바꿀 수 없다는 것입니다. 지금까지 만들어진 소프트웨어는 이전 세대들의 ISA를 조립해서 만들어졌기 때문입니다. 갑자기 ISA가 통째로 바뀌어버리면, 똑같은 명령어가 없기 때문에 소프트웨어도 전부 다 바꾸어야 합니다. 이런 이유로 x86 ISA는 처음 개발된 지 수십년이 지난 지금도 쉬이 바꾸지 못하고 있습니다. 모바일 시대가 도래하며 완전히 새로운 소프트웨어 스택을 개발하는 과정에서 ARM이 크게 주목받을 수 있었을 뿐입니다.
간단한 CPU를 만들어보자
이번 포스팅에서는 많은 것들을 간소화한 아주 간단한 CPU를 만들어봅니다. 이를 통해 CPU를 만들기 위해서는 어떤 Building Block이 필요한지 차근차근 살펴보고, 결론적으로는 왜 CPU가 딥러닝 연산에는 아쉬운 프로세서가 되었는지 알아봅니다.
우리가 만드는 CPU는 세 가지 명령어로 이루어진 ISA를 수행합니다. (5,000페이지를 3줄로 퉁쳐버리는..)
메모리에서 데이터 불러오기
메모리에 데이터 저장하기
덧셈
Instruction의 길이는 32자리 - 혹은 32비트입니다.
우리가 만들어볼 CPU의 Instruction의 구조는 아래와 같습니다.
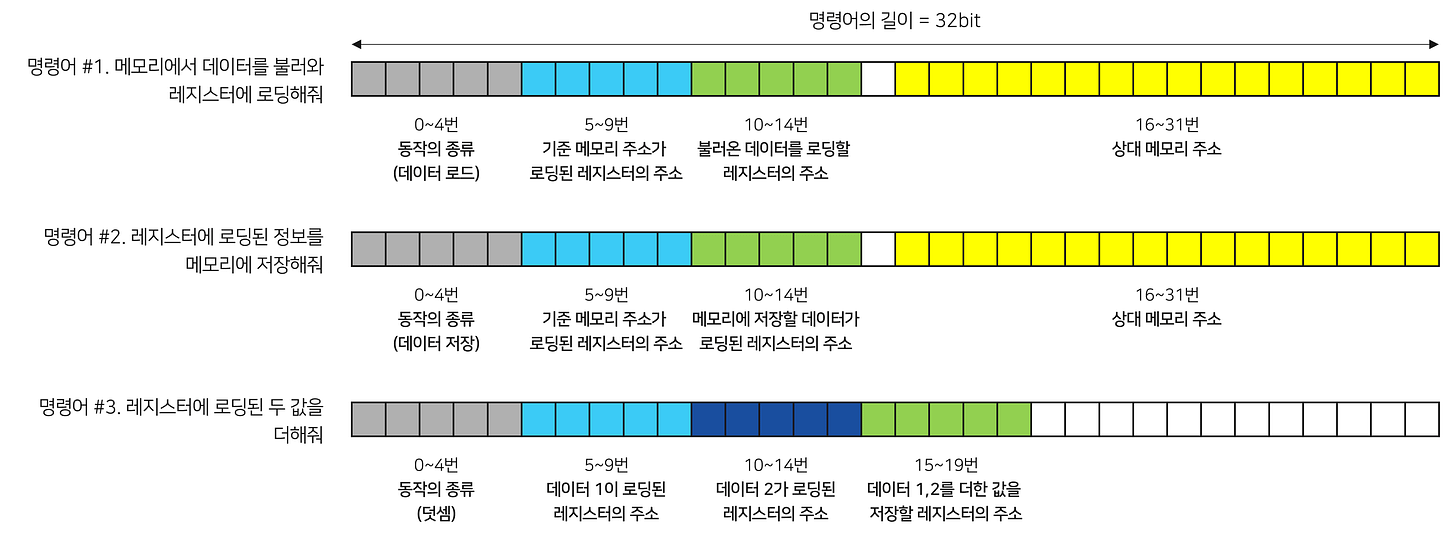
모든 ISA는 위와 같이 명령어의 어떤 부분에 어떤 내용이 포함되어 있는지 세세히 알려줍니다. 그리고 위의 내용과 조금이라도 다른 방식으로 코딩하면 오류가 발생하게 됩니다.
지금부터 본격적으로 CPU를 만들어 볼 텐데요. 아주 많은 것이 간소화되어 있는 만큼 보다 엄밀한 설명을 원하실 분들을 위해 Onur Mutlu 교수님의 명강의를 함께 남겨둡니다.
명령어 1: 데이터 로드

프로세서에는 명령어를 저장하는 “Instruction memory”가 있습니다. Instruction memory에는 앞으로 프로세서가 수행할 명령어들이 잔뜩 쌓여있습니다. 마치 할일이 많은 제 일상을 보는 듯 합니다(?) 뒤이어서 나오는 Instruction memory는 모두 IM으로 짧게 줄여 설명하도록 하겠습니다.
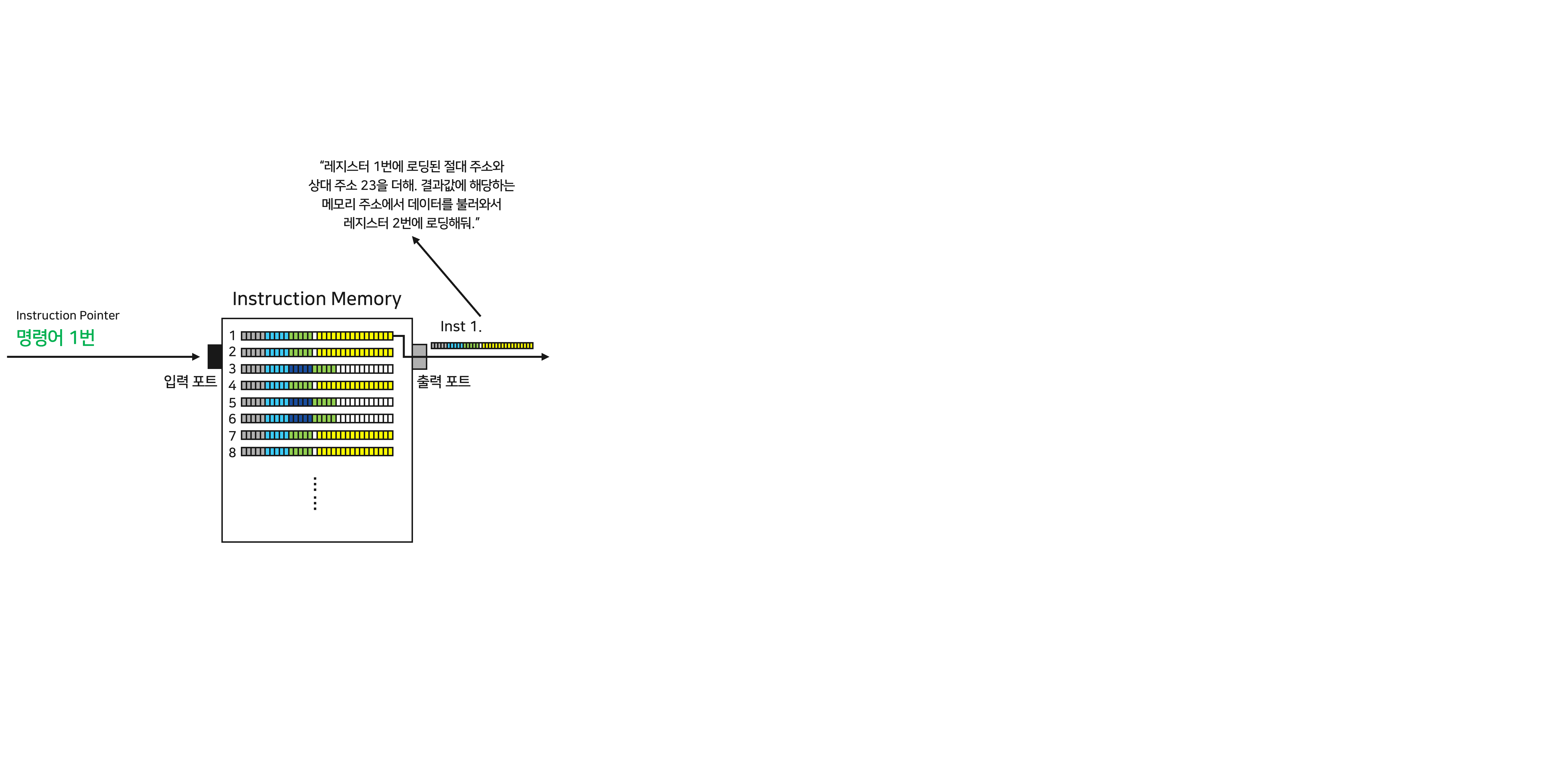
이제 “Instruction Pointer (IP)”라는 녀석이 IM에 저장된 할일 리스트 중 어떤 명령어를 수행할지 알려줍니다. 지금은 IM 명령어 1번을 수행하라고 지시하고 있네요. 이 정보가 IM으로 흘러들어가, 명령어 1번이 튀어나옵니다. 첫 번째 명령어 - Inst1 은 메모리에서 데이터를 불러오는 명령어입니다.
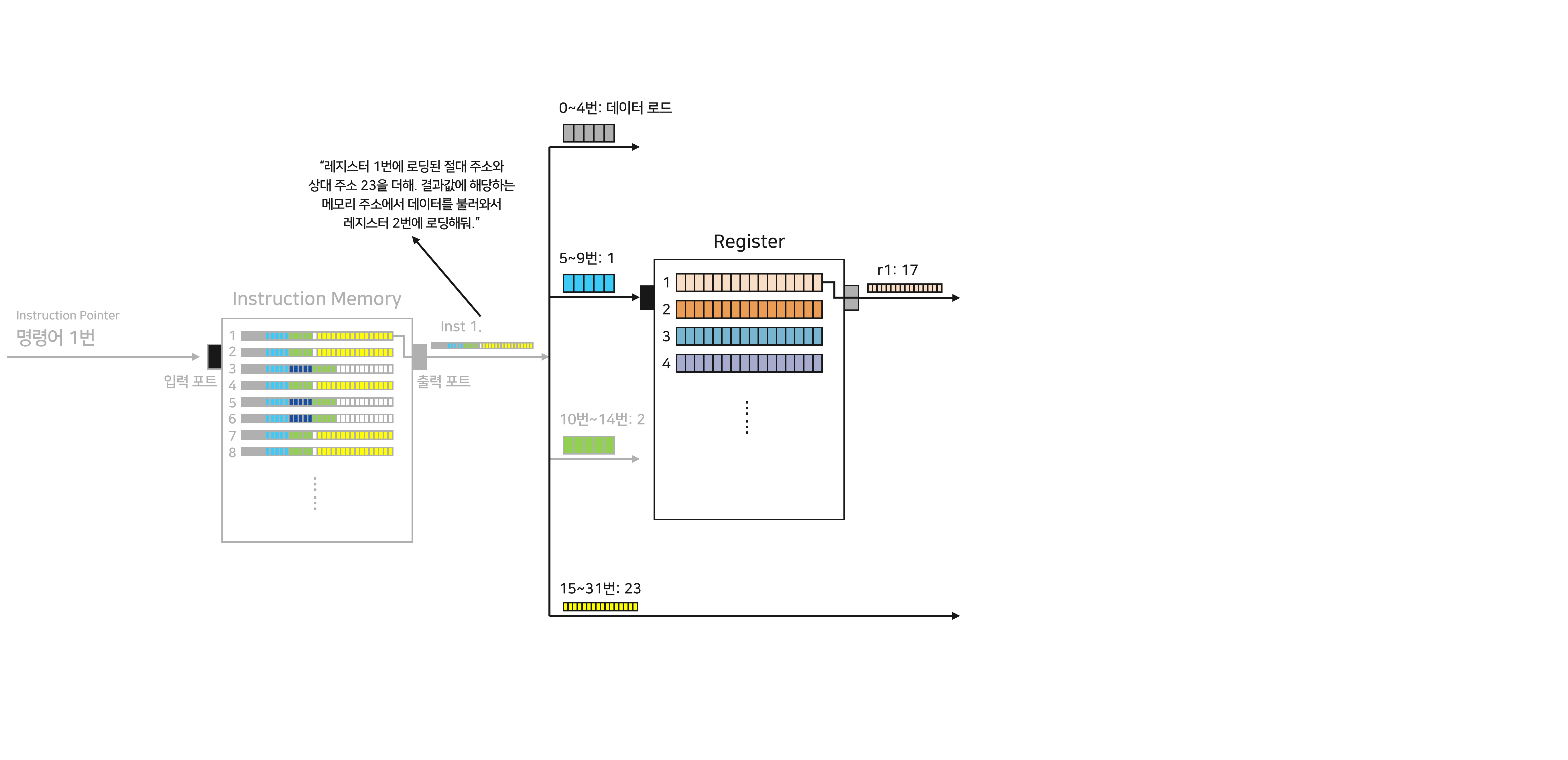
프로세서에는 임시 저장공간인 “Register”가 있습니다. 레지스터는 메모리에서 데이터를 전달 받아, 앞으로 있을 연산에 필요한 데이터를 임시로 저장하기도 하고, 연산 결과 값을 메모리에 보내기 전에 임시로 저장하는 역할을 합니다. 이번 포스팅에서는 이러한 “임시 저장”의 특성을 반영해 “레지스터에 로딩한다/로딩되었다”는 표현을 활용하도록 하겠습니다.
Inst 1의 5번~9번 정보는 먼저 레지스터 1번 공간, 혹은 r1에 로드된 값을 준비하라고 명령합니다. r1에는 숫자 “17”이 저장되어 있었네요.
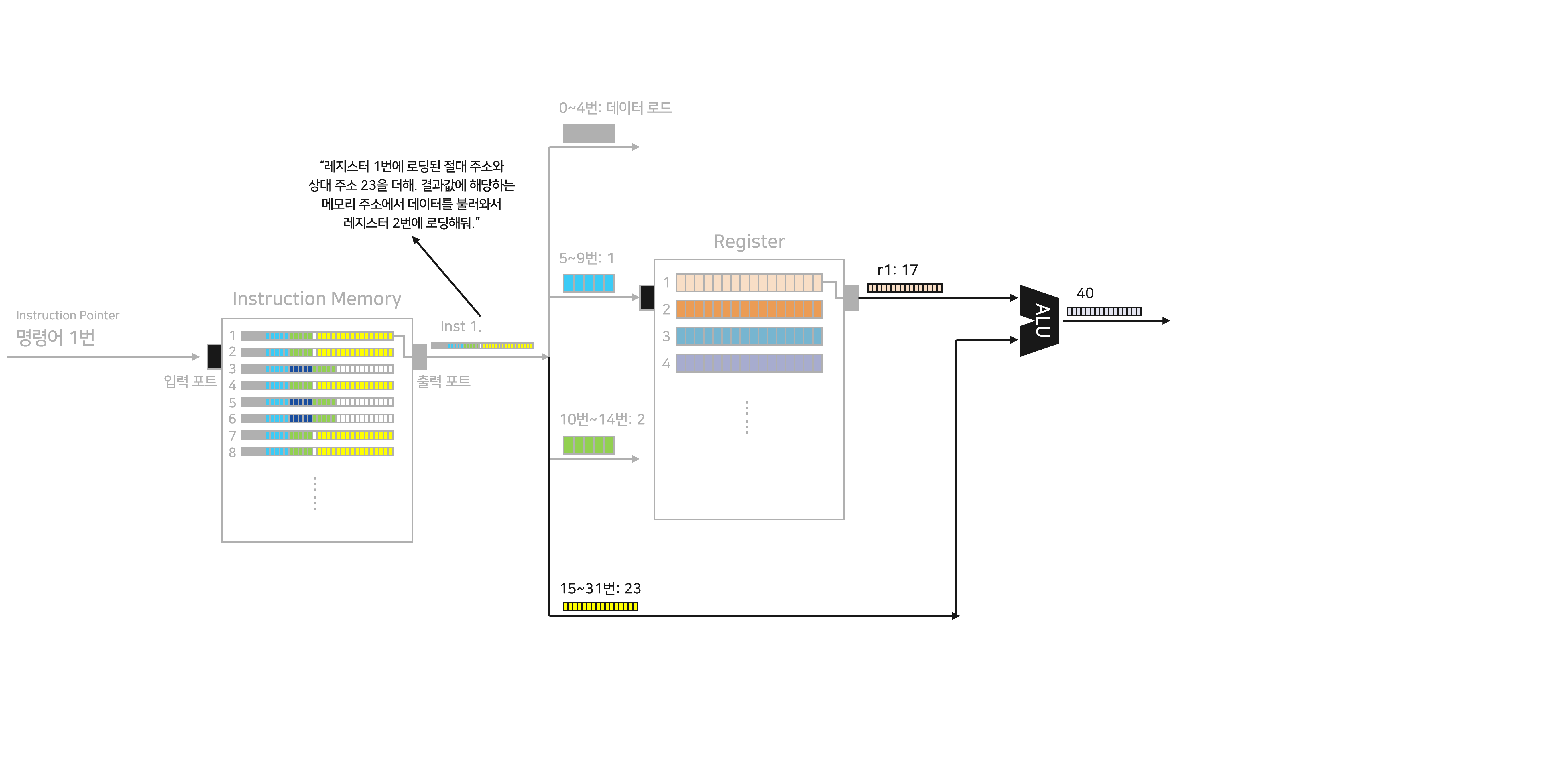
Inst 1은 r1에서 가져온 데이터와 Inst 1의 15~31번에 지정된 상대 주소를 더하라고 명령하고 있습니다. 그래서 프로세서는 r1의 정보와 15~31번에 저장된 상대 주소를 ALU(Arithmetic Logic Unit)에 입력해, 덧셈을 수행합니다.
ALU는 여러 연산을 수행할 수 있는 똑똑한 녀석입니다. 다만 우리가 만드는 ISA에서는 덧셈 말고 별달리 할 연산이 없습니다. 이번 포스팅의 ALU는 덧셈만 할 줄 안다고 가정하겠습니다.
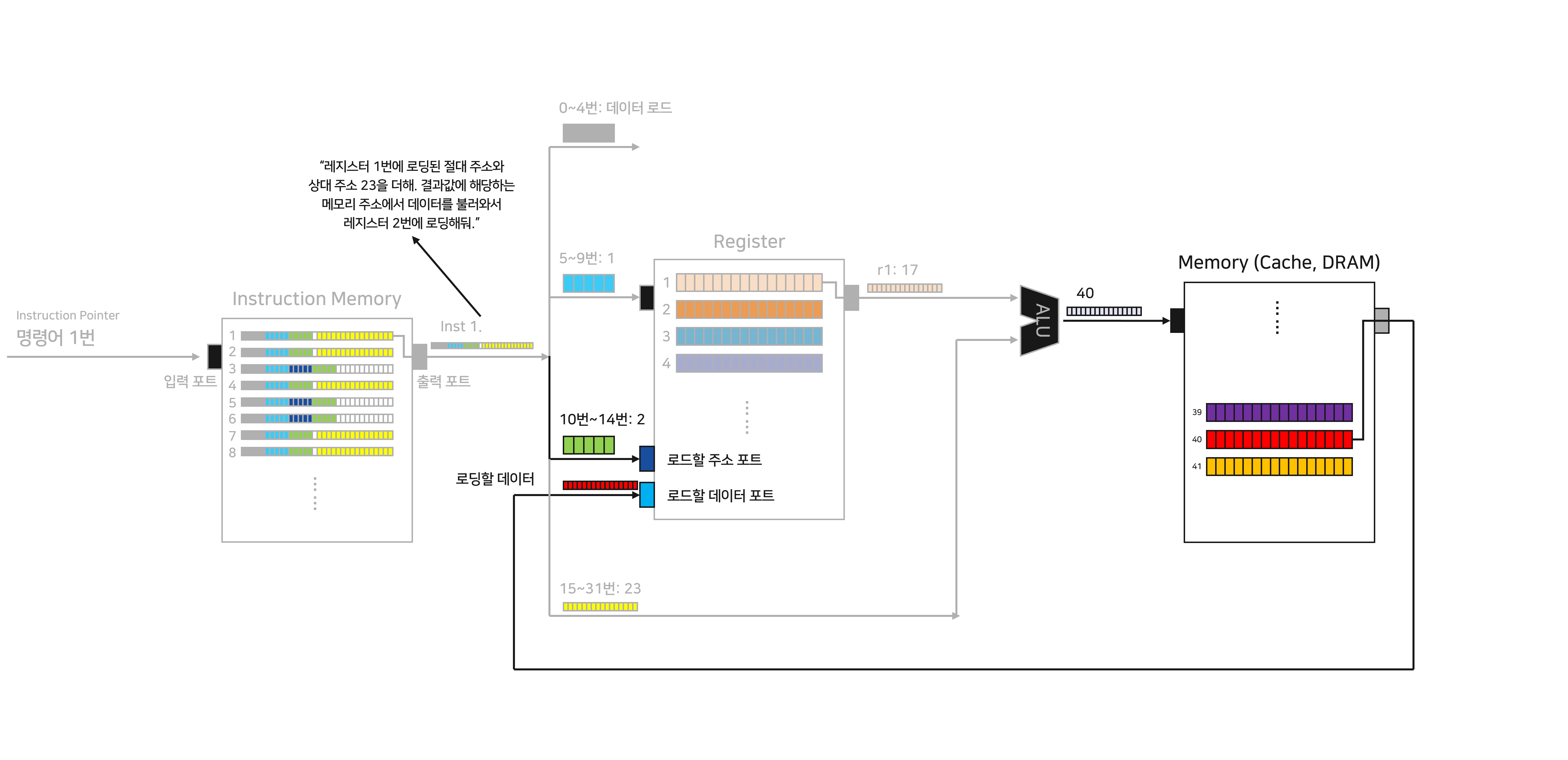
Inst 1은 이렇게 더한 값을 메모리로 전달하고, 해당 주소에 있는 데이터를 레지스터로 불러오라고 명령하고 있습니다. 두 값을 더하니 40이 나왔고, 메모리에서 40번 주소에 찾아가 붉은색 데이터를 가져옵니다.
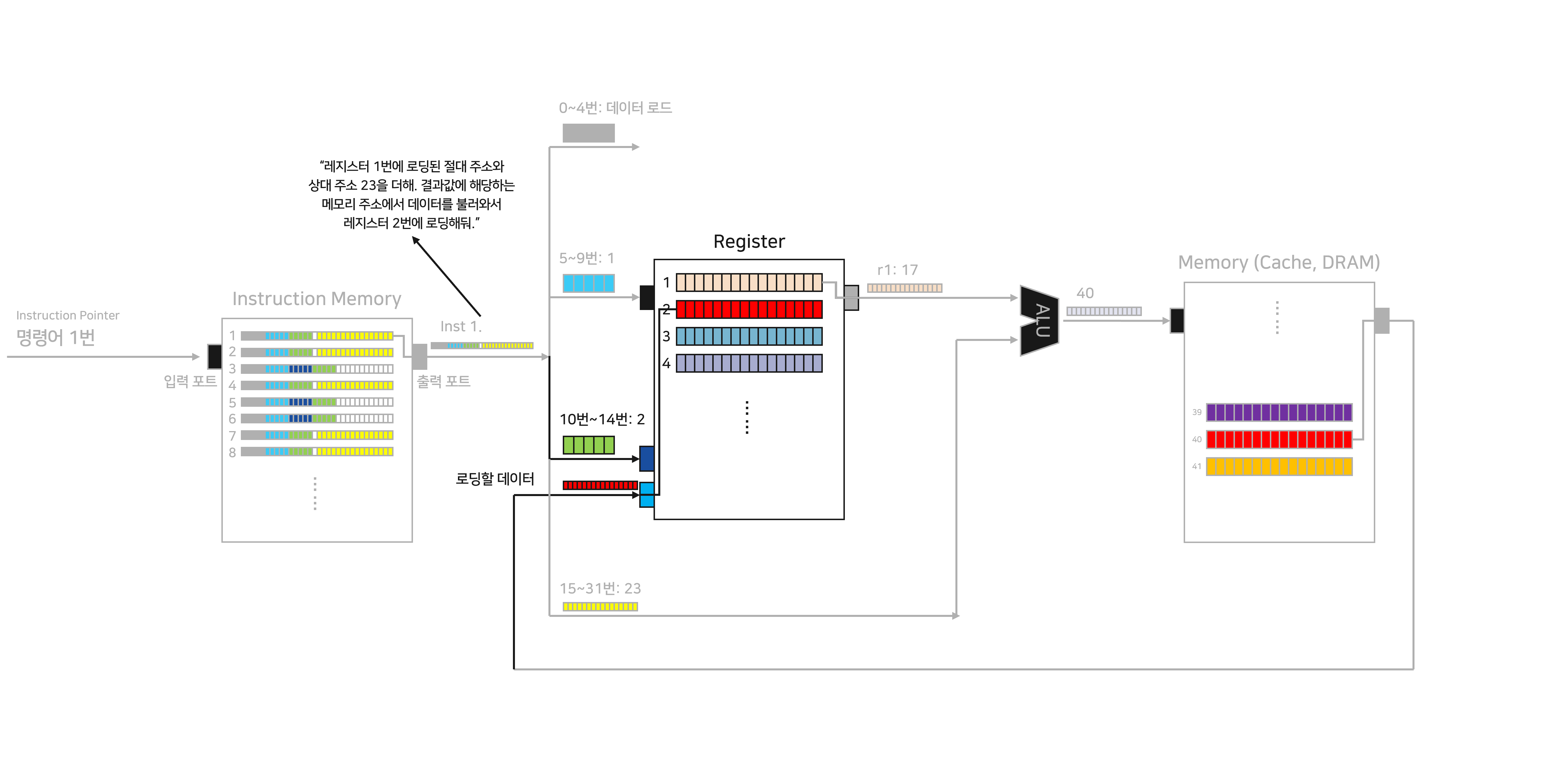
Inst 1은 10~14번 위치에 저장된 레지스터 주소에 데이터를 로드하라고 지시합니다. 10~14번 위치에는 “2”가 저장되어 있었습니다. 이에 따라 메모리에서 가져온 데이터를 레지스터의 2번 주소에 로드합니다. 원래는 주황색이던 데이터가 붉은색으로 바뀌었습니다.
이로써, 우리는 벌써 ISA의 1/3을 수행할 수 있는 프로세서_v0.1을 만드는 데 성공했습니다. 생각보다 평화로운 전개네요.
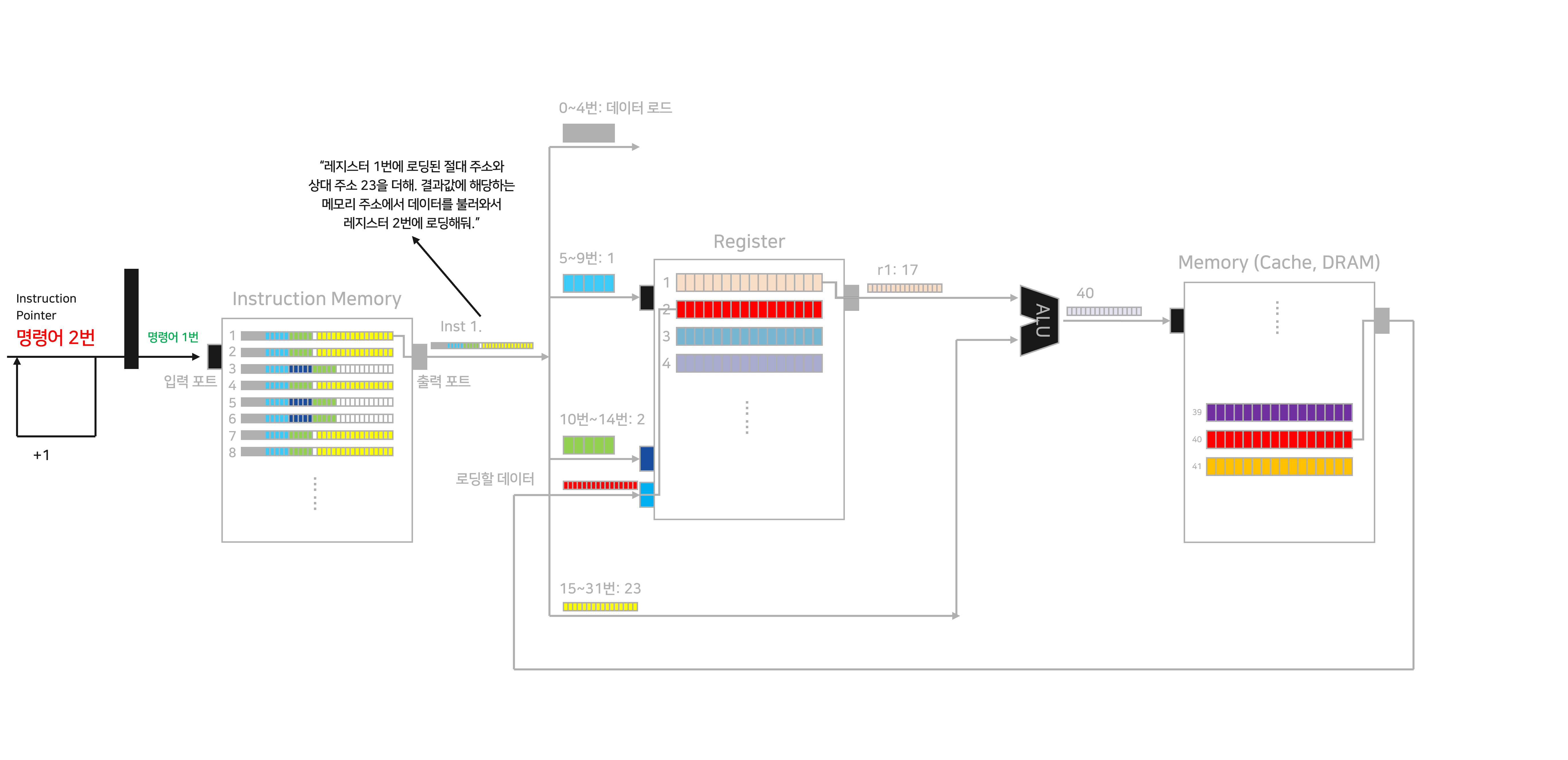
아, 그리고.. Inst 1이 수행되는 사이 Instruction Pointer, IP가 다음 명령어를 가리킬 수 있도록 값을 변경해주어야 합니다. 이번 프로세서에서는 간단하게 1을 더하기로 합니다.
이제 IP는 명령어 2번을 수행하라고 지시하고 있습니다. 우리가 만드는 프로세서는 살짝 멍청해서 IP가 적당한 값을 가르쳐주지 않으면 어떤 명령어를 수행하면 되는지 갈팡질팡하게 됩니다.
그리고 명령어 1번을 수행하는 과정에서는 새로운 명령어를 가리키면 안됩니다. 아래와 같이 잘못된 명령어를 수행하게 되기 때문입니다.
우리는 40번 메모리에서 붉은색 데이터를 레지스터에 로드하는 명령어를 수행하고 있습니다.
명령어 1번은 이 데이터를 레지스터 2번에 로드하기를 원하는데요. 명령어 2번이 대뜸 들어와서 레지스터 5번에 데이터를 로드하라고 명령합니다.
이 때문에 프로그램에서 원하는 것과 달리 붉은색 데이터를 레지스터 5번에 저장하는 상황이 연출됩니다.
그래서, 우리는 IP가 프로세서에 전달되는 길목에 하나의 셔터를 배치합니다. 이 셔터를 통해 업데이트된 IP가 지금 수행되는 명령을 방해하지 않도록 예방하고, 모든 명령 수행이 완료한 뒤에 새로운 IP를 전달받을 수 있도록 합니다.
더해서 셔터를 통과한 명령어 1번은 명령이 완료될 때까지 계속해서 그 값을 유지해야만 합니다. 데이터를 가지고 오는데 갑자기 명령어가 사라져, 어디에 데이터를 저장할지 알 수 없으면 그 역시 난감하기 때문입니다. 따라서 이 셔터는 뒤따라오는 데이터를 막아주는 한편, 통과한 데이터를 지속시키는 일종의 “메모리” 역할을 하게 됩니다. 여기서 활용되는 메모리의 구조는 CPU, TPU, GPU 뒤에 따라올 메모리 구조에서 상세히 설명하도록 하겠습니다.
명령어 2: 데이터 저장

1번 명령어 수행이 완료된 뒤, 셔터가 열리면서 프로세서에 새로운 IP가 진입합니다. 명령어 2번을 가리키고 있네요. 명령어 2번 - Inst 2는 메모리에 데이터를 저장하라고 지시하고 있습니다.

Inst 2는 크게 먼저 두 가지 업무 수행을 지시하고, 프로세서는 별 문제 없이 이를 수행합니다.
Inst 2의 5~9번이 가리키는 레지스터 1번(r1)에서 데이터를 수집니다.
Inst 2의 10~14번이 가리키는 레지스터 3번(r3)에서 데이터를 수집합니다.

뒤이어 오는 업무는 다음과 같습니다:
r1 데이터와 Inst 2의 15~31번의 상대 주소를 더합니다. 첫 번째 명령어를 수행할 때와 마찬가지로 ALU에 두 값을 입력해 결과값을 만들어냅니다. 이번에는 메모리의 “41번” 주소를 가리킵니다.
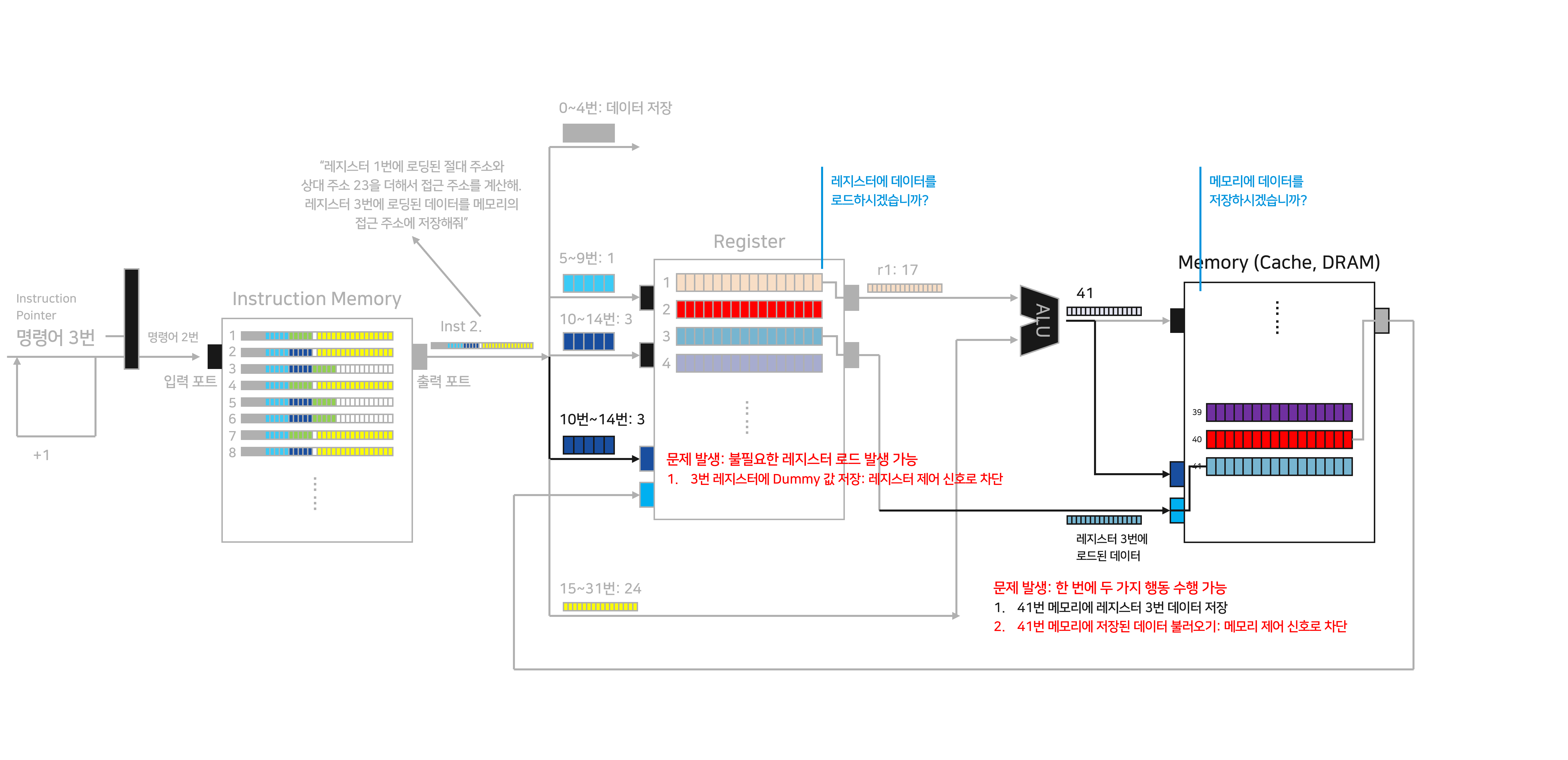
이제 Inst 2는 메모리의 “41번” 주소에 읽어들인 r3의 데이터를 저장하도록 지시합니다. 여기서 몇 가지 문제가 생깁니다.
문제 1: 메모리에서 한 번에 두가지 행동을 수행할 수 있습니다.
41번 메모리에 r3 데이터를 저장 (명령: 데이터 저장)
41번 메모리에 저장된 데이터를 불러와서 레지스터에 로드 (명령: 데이터 로드)
이 문제를 해결하기 위해, 우리는 메모리에게 지금의 명령어가 “데이터를 저장하는 명령어인지”를 알려주는 제어 신호를 전달하려고 합니다. Inst 2에서는 “예(1)” 신호를 전달해 메모리에 데이터를 저장하게 됩니다.
문제 2: Inst 2의 10~14번 데이터가 “로드할 주소 포트”에 전달되고 있습니다. 이 데이터를 막지 않으면 예상치 못한 Dummy 데이터가 레지스터 3번에 저장될 수도 있습니다.
이 문제를 해결하기 위해, 위와 비슷하게 “레지스터에 데이터를 로드하는 명령어”임을 알려주는 제어 신호를 전달합니다. Inst 2의 경우 레지스터에 데이터를 로드하는 명령어가 아니므로, 불필요한 데이터가 저장되는 것을 막을 수 있습니다.
두 번째 명령어를 수행할 수 있도록 만들다보니, 점점 프로세서가 복잡해지고 있습니다. 조금은 답답하게도, CPU의 각 구조물들에게 계속해서 우리가 “어떤 명령어를 수행하고 있는지”를 알려주는 제어 신호를 전달해야 합니다. 데이터만을 입력하면 여러 개의 다른 행동을 취할 수 있기 때문에, 수행하고 있는 명령어의 종류를 상기시켜줘야 한다는 것이죠.
다르게 이야기하면 수천, 수만 개의 서로 다른 명령어를 수행하는 데 있어서는 훨씬 방대한 양의 “제어 신호”가 필요함을 의미합니다. CPU가 단순하고 반복된 연산에서 불리한 하나의 이유는 다양한 명령어를 수행을 위한 제어 신호를 만드느라, 오롯이 연산에만 집중하기 어려운 구조를 가지고 있기 때문입니다.
무튼, 우리는 이로서 ISA의 2/3를 수행할 수 있는 프로세서_v0.2 개발에 성공했습니다.
명령어 3: 덧셈
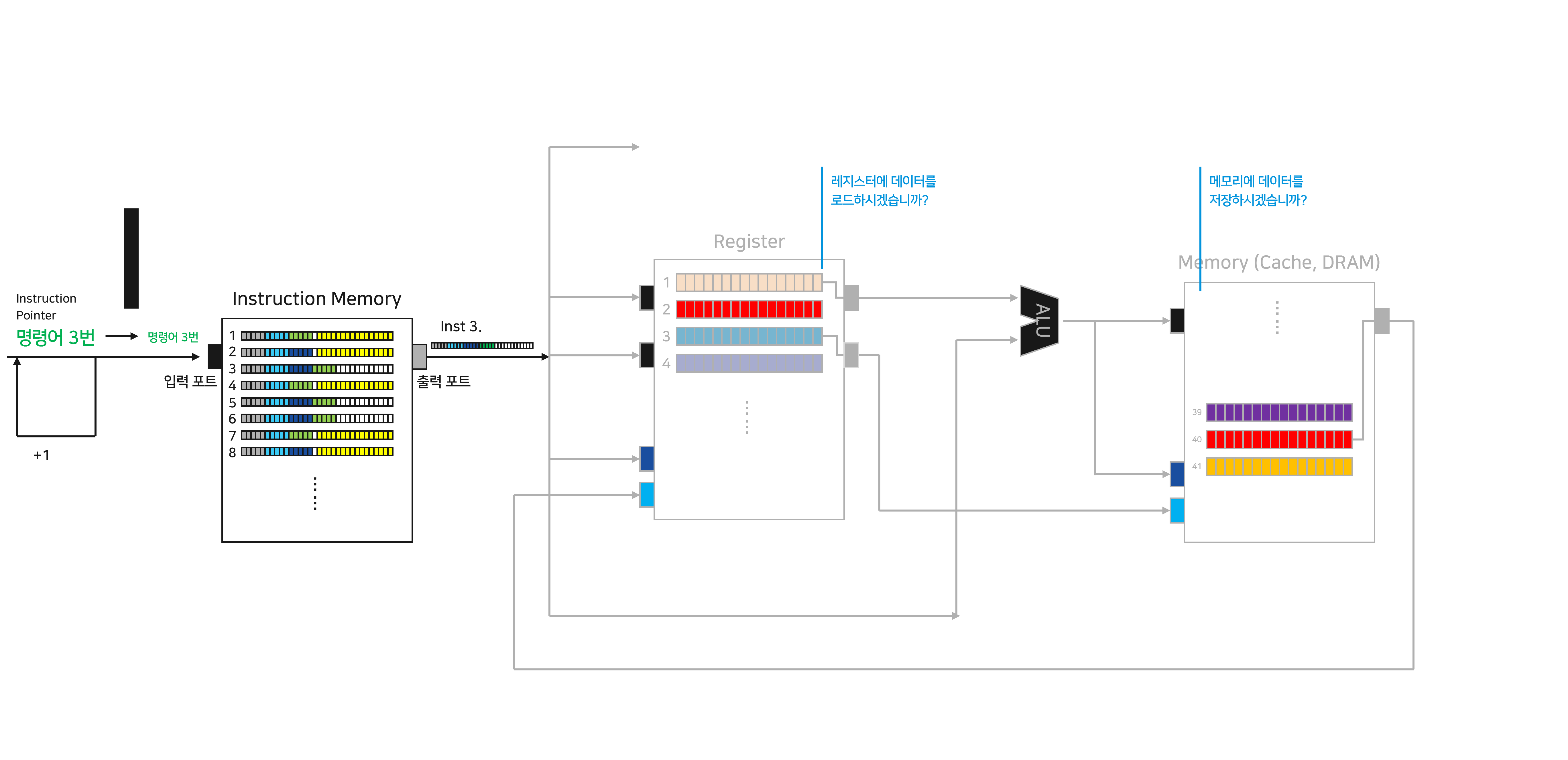
Inst 2가 완료된 뒤, 셔터가 열리면서 프로세서에 새로운 IP가 진입합니다. 명령어 3번을 가리키고 있네요. 명령어 3번 - Inst 3는 덧셈을 하는 명령어입니다.
셔터가 닫힘과 동시에 IP는 명령어 4번을 가리키기 시작합니다.
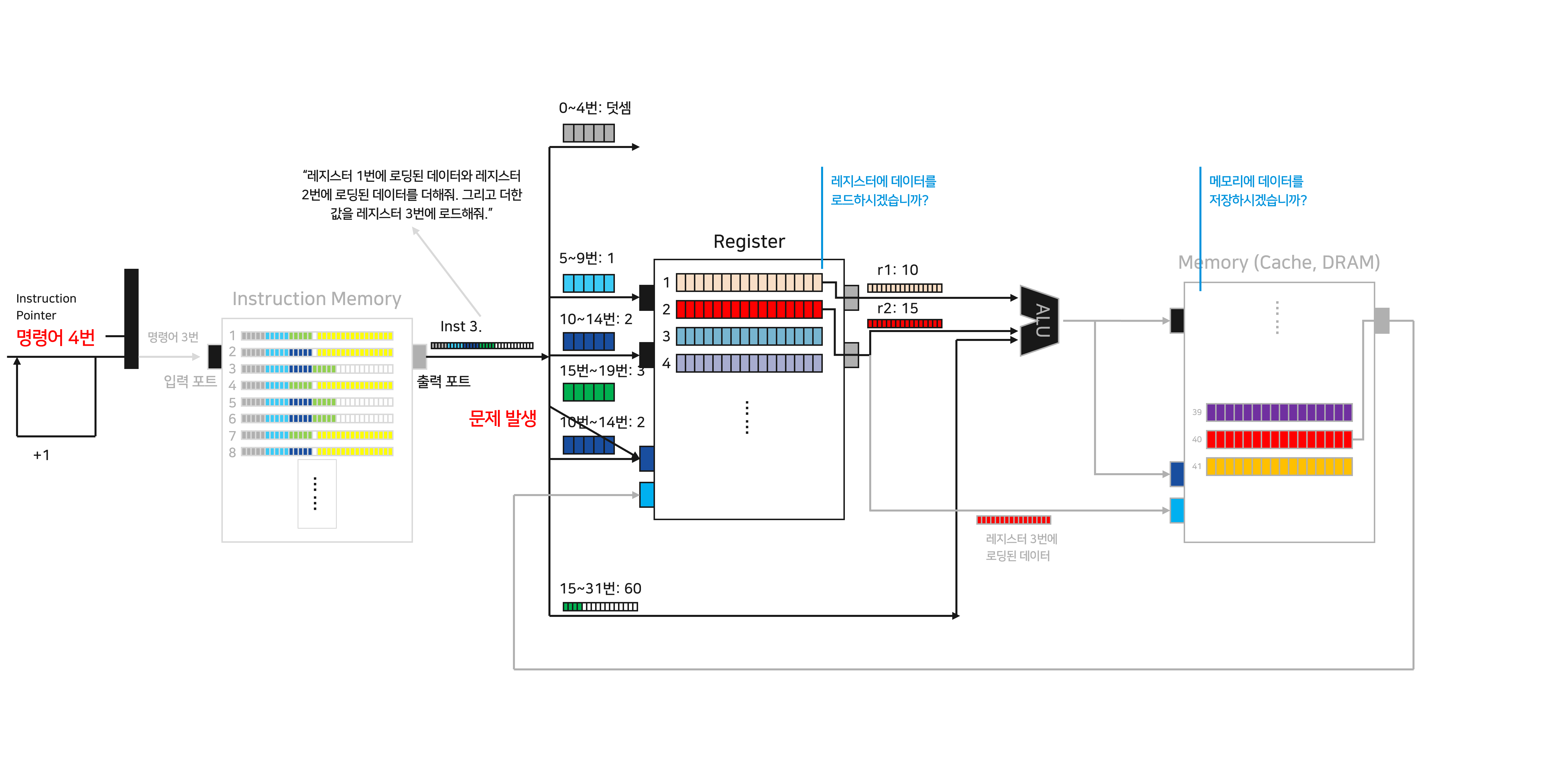
동시에 Inst 3 역시 프로세서 내에서 단계별로 업무를 수행하고 있습니다. 지금까지와 같은 방식으로 Inst 3로 여러 조각의 정보들로 이루어져 있습니다. 이들을 분해해서 데이터를 전달하기 시작하는데, 한가지 문제가 발생합니다.
기존의 Inst 1에서는 10~14번 위치의 데이터를 “로드할 주소 포트”에 전달했습니다. 하지만 Inst 3에서는 15~19번 위치의 데이터를 “로드할 주소 포트”에 전달하라고 지시합니다. Inst 1 수행을 위해서 이미 “로드할 주소 포트”에 10~14번 위치에 데이터를 연결해두었기 때문에, Inst 3을 위해 15~19번 주소를 또 연결하게 되면 포트에 두 개의 정보가 동시에 전달되는 문제가 생깁니다.
충돌이 발생하기 때문에 이들 중 한 값만을 선택해서 포트에 전달해야 합니다.
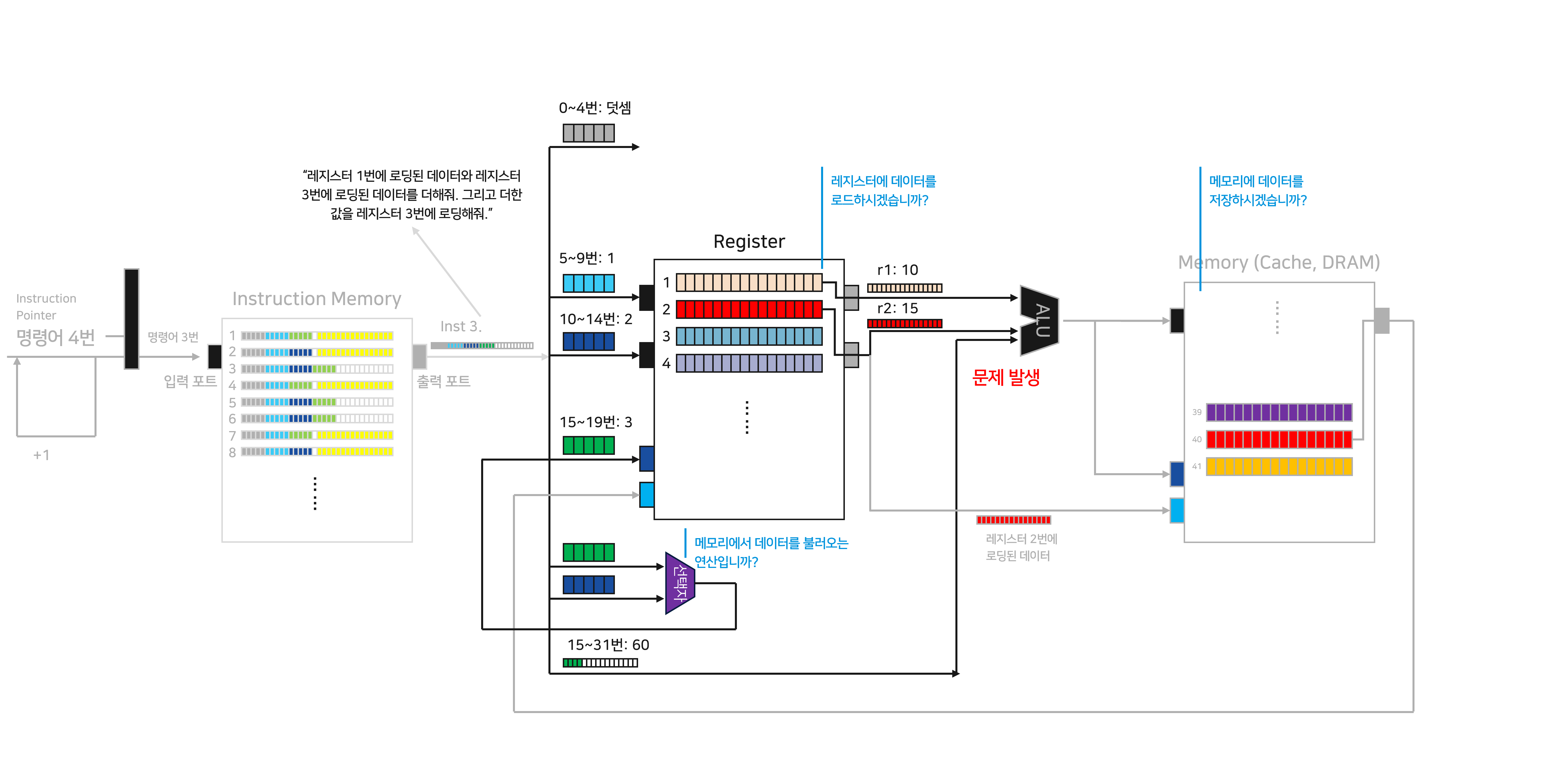
이 문제를 해결하기 위해 “선택자”라는 연산자를 활용해보겠습니다. 두 개의 데이터를 입력하고, 둘 중 어떤 데이터를 활용할지에 대한 제어 신호를 넣으면 원하는 데이터를 선별할 수 있습니다. 이번에는 “데이터 로드”와 “덧셈”을 구분할 수 있는 제어 신호가 필요하겠네요. 선택자에 “메모리에서 데이터를 불러오는 연산인지”를 알려주는 제어 신호를 전달합니다. Inst 3에서는 “아니오(0)” 신호가 전달되고, 이에 따라 10~14번에 저장된 값이 선택되어 포트에 전달됩니다. 새로운 명령어를 수행하려니, 명령어들을 구분짓는 제어 신호, 선택자가 추가되기 시작합니다.
그런 와중에 프로세서가 꿋꿋이 자신의 할일을 합니다. 해야 하는 일은 다음과 같습니다:
To do 1
명령어의 5~9번 정보가 지시하는대로 레지스터 1번(r1)의 데이터를 수집합니다.To do 2
명령어의 10~14번 정보가 지시하는대로 레지스터 2번(r2)의 데이터를 수집합니다.To do 3: 수집한 두 데이터를 더합니다.
To do 3를 진행하려는데, 또 다른 문제가 발생합니다. Inst 3에서는 상대 주소를 활용하지 않지만, 이전의 명령어들을 수행하기 위해 15~31번 데이터가 ALU에 전달되고 있기 때문입니다. 직전에 해결했던 문제와 마찬가지로 두 개의 다른 정보가 하나의 포트에 입력되는 문제에 마주합니다.
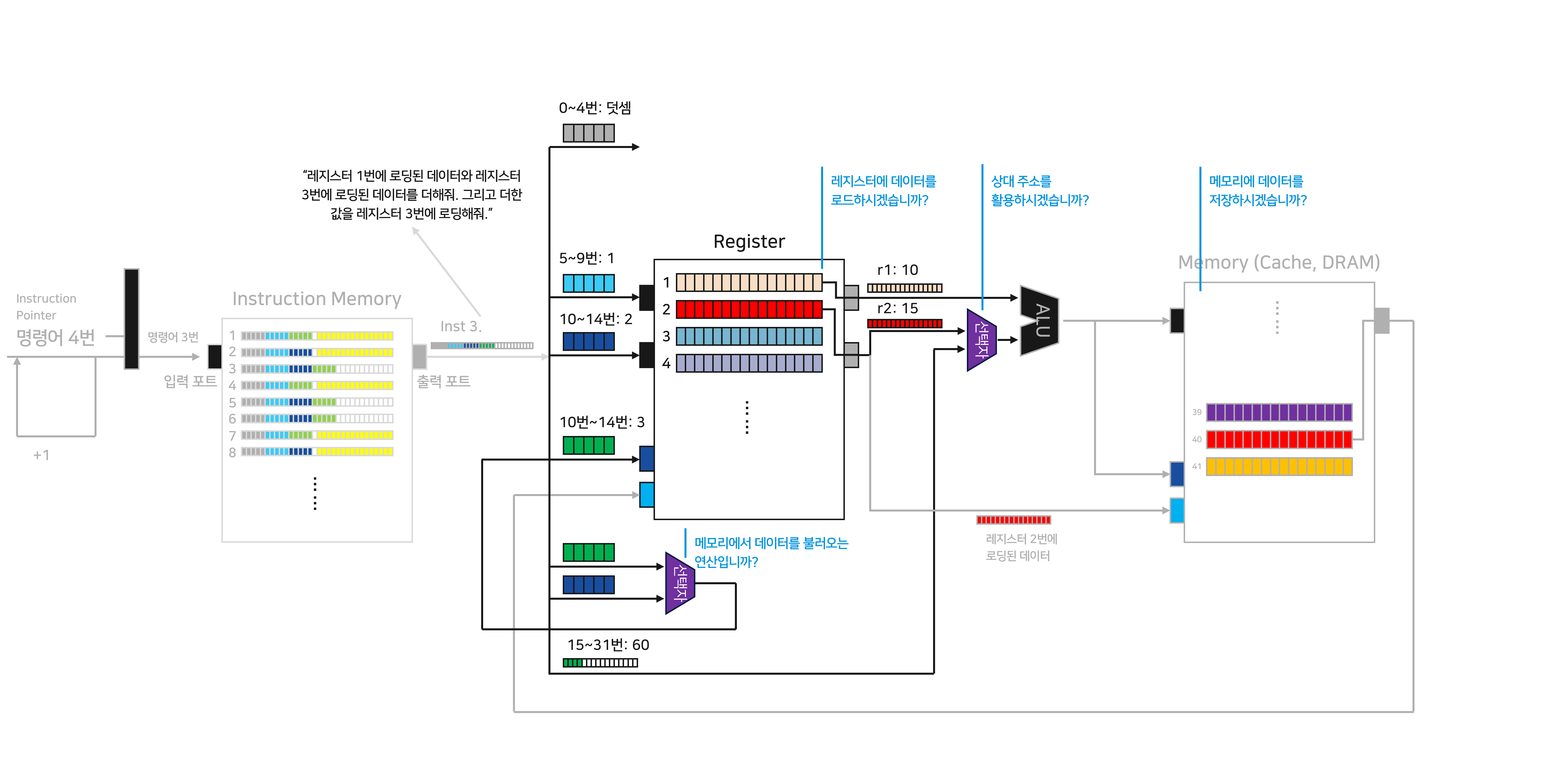
같은 문제이므로 이를 해결하기 위해 마찬가지로 “선택자”를 활용합니다. 이번에는 “상대 주소를 활용할지”를 알려주는 제어 신호를 선택자에 전달합니다. Inst 3에서는 “아니오(0)” 신호가 전달되고, 이에 따라 r2 값이 선택되어 ALU로 전달됩니다. 문제 없이 r1과 r2의 값을 더해 ‘25’라는 결과값이 생성되었습니다.
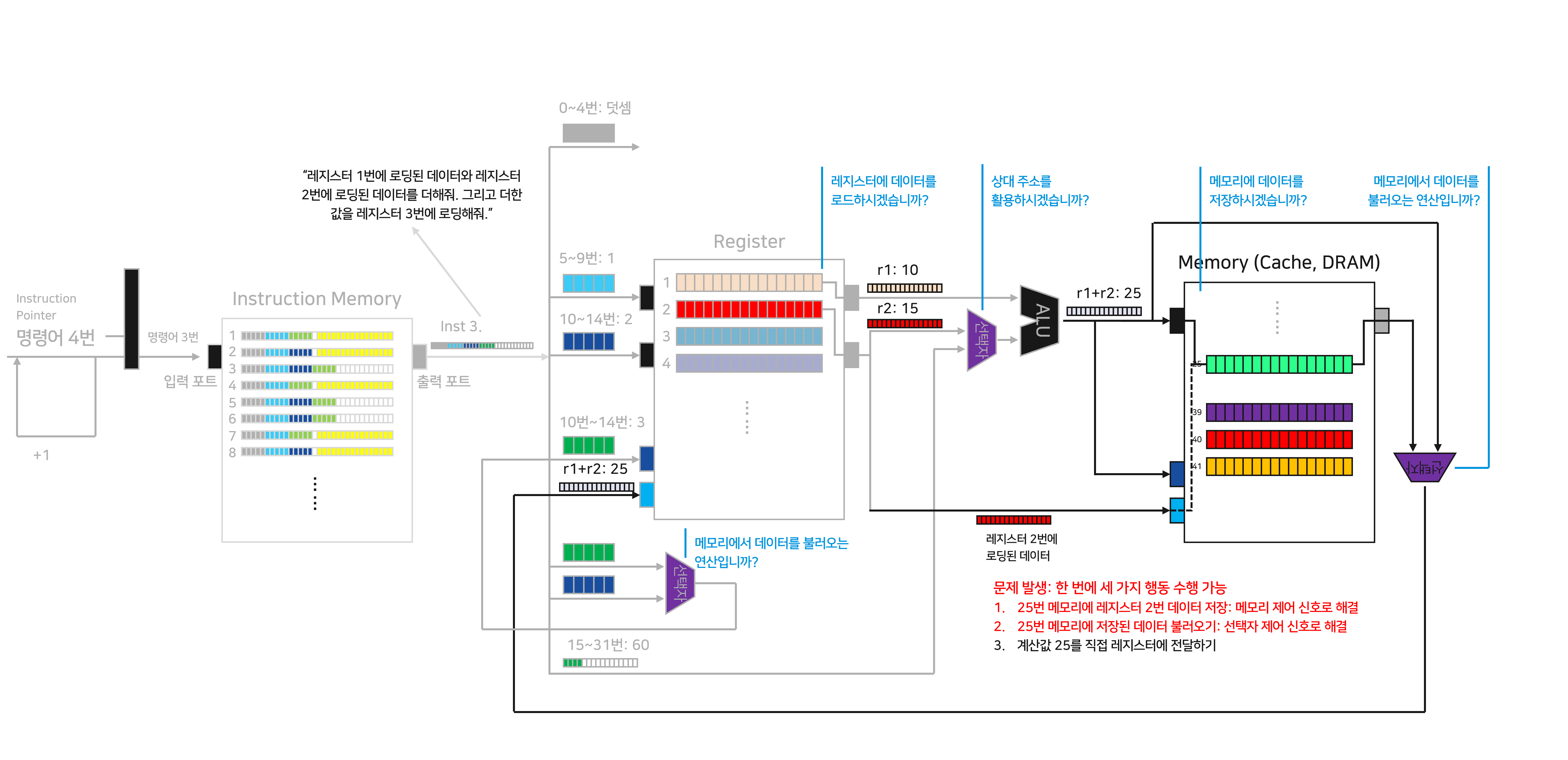
우리는 이제 두 값을 더한 “25”를 레지스터에 전달해야 합니다. 하지만 메모리에서 꽤 많은 장벽이 우리를 가로막고 있습니다.
문제: 메모리에서 세 가지 행동을 취할 수 있습니다.
25번 메모리에 r2에서 전달되어온 데이터 저장 (명령어: 데이터 저장)
“메모리에 데이터를 저장하는지”를 알려주는 제어 신호를 전달해 해결합니다. Inst 3에서는 “아니오(0)” 신호를 전달해 데이터 저장을 수행하지 않도록 차단합니다.
25번 메모리에 저장된 값을 읽어서 레지스터에 전달 (명령어: 데이터 로드)
이를 구분하기 위해 메모리에서 출력된 값과 연산의 결과값을 입력하는 선택자를 추가합니다. 여기에 “메모리에서 데이터를 불러오는 연산인지”를 알려주는 제어 신호를 전달하니다. Inst 3에서는 “아니오(0)” 신호를 전달해 연산의 결과값을 레지스터로 전달합니다.
연산의 결과값 25를 직접 레지스터에 전달 (명령어: 덧셈)
위의 방법을 통해 최종적으로 마지막 행동을 선택하도록 유도합니다.
무려 두 개의 제어 신호를 활용해, 난관을 헤치고 덧셈의 결과값이 레지스터의 “로드할 데이터 포트”에 도달합니다. 물론 지금의 구조가 가장 효과적인 구조는 아닙니다. 모든 것을 단순화했다는 사실을 기억해주세요! “여러 개의 다른 명령어를 처리하기 위해 이를 구분하기 위한 building block이 점점 추가되고 있다”는 것이 핵심입니다.

레지스터의 “로드할 주소 포트”에 Inst 3의 10~14번 데이터 - 3이 입력되고 있습니다. 이번에는 “레지스터에 데이터를 로드할지”를 알리는 제어 신호에 “예(1)”을 전달하여 결과값을 레지스터 3번에 저장합니다.
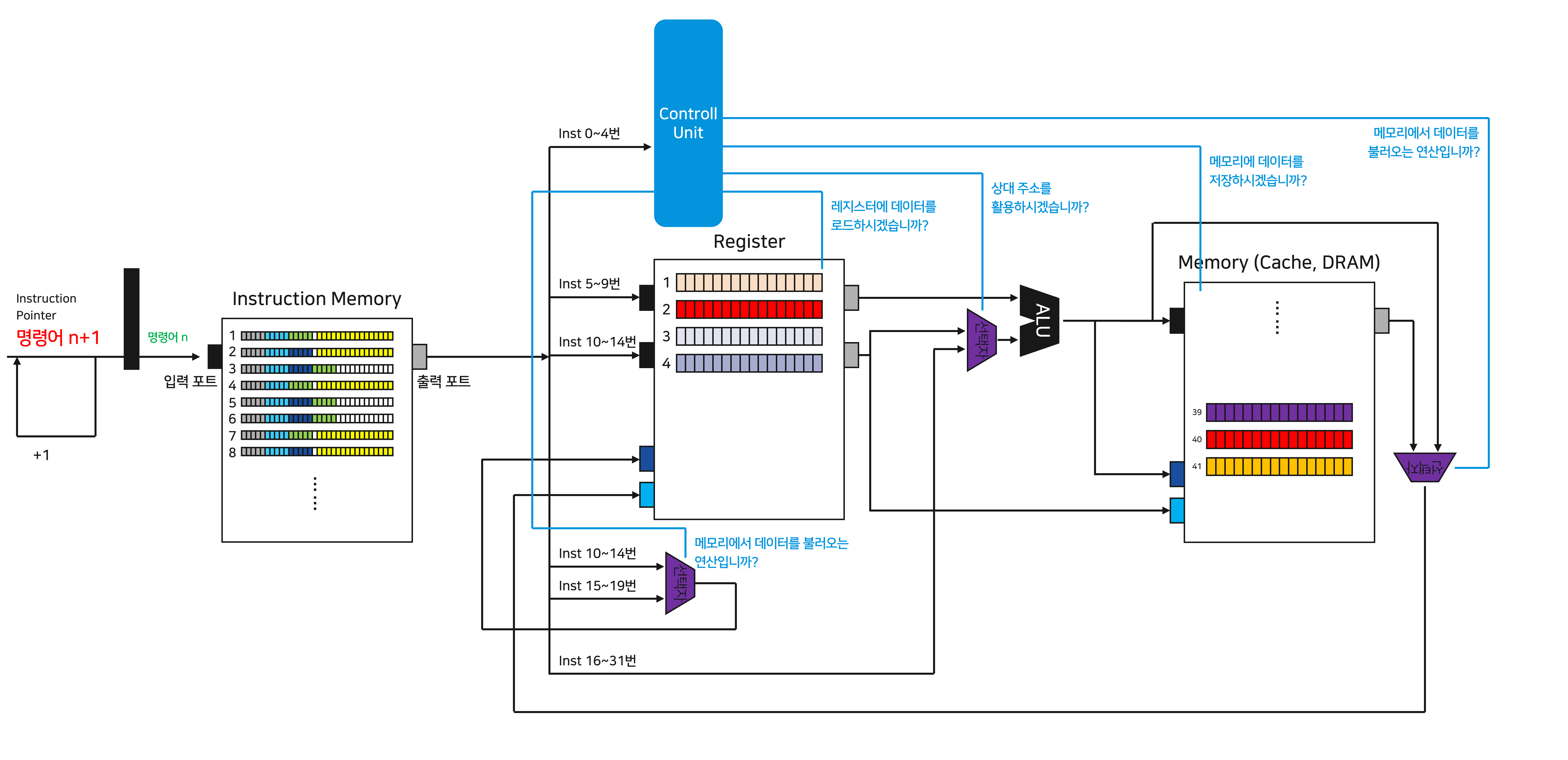
앞서서 필요로 했던 모든 제어 신호들은 0번~4번에 저장되어 있는 명령어를 통해 “제어 장치(Control Unit)”에서 추출된 정보들로 만들어집니다. 이번 포스팅에서는 제어 장치가 어떻게 작동하는지 까지는 자세히 설명하지 않습니다. 이렇게 우리는 3줄 짜리 ISA를 수행할 수 있는 초간단 CPU를 개발하는 데 성공했습니다. 기념할 겸, 프로세스_v1.0이라고 이름 붙이도록 하겠습니다.
지금까지의 모든 내용은 아래 출처에서 더 자세하고 정확하게 확인하실 수 있습니다.
지금까지 읽으셨다면 생각보다 “연산”에 대한 고민이 별로 없다는 것을 느끼실 수 있습니다. 오히려 수많은 제어 신호들과 이들로 인해 행동을 바꾸는 선택자들을 배치하는 것이 이번 설계 과정에서의 핵심이었습니다. 그리고 제어 신호를 구축하는 가장 핵심적인 이유는 우리가 “다양한 명령어”을 취급하고 있기 때문입니다. 3개 뿐임에도 불구하고 이렇게까지 많은 제어 신호가 필요했는데, 수천~수만 개의 명령어를 수행하는 실제 CPU의 제어 신호는 얼마나 복잡할까요.
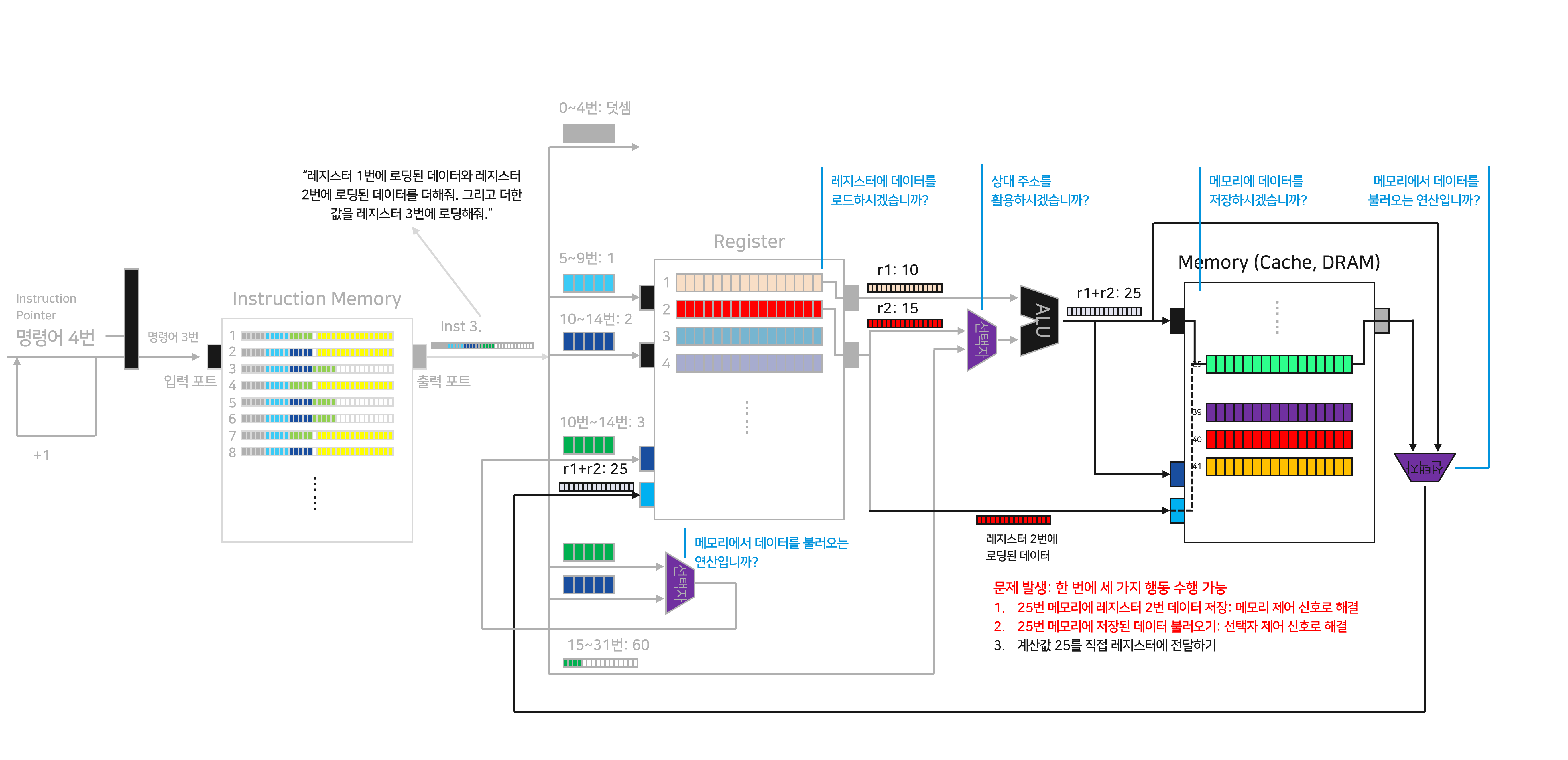
자, 이제 다시 본론으로 돌아와서. 지금의 프로세서_v1.0은 감격스러운 개발의 결과이긴 하지만 굉장히 구립니다. 위 그림은 저희가 방금 전에 프로세서를 만들던 과정에서 살펴보았던 그림인데요. 진한 영역을 제외한 Instruction Memory, Register는 아무런 일도 하지 않고 있습니다. 개발한 프로세서_v1.0은 작업을 하는 과정에서 특정 부분만 일하고, 나머지는 놀고 있는 모양입니다. 할일이 얼마나 많은데, 하나의 구성 요소도 쉬게 놔두어서는 아니됩니다.
Pipelined Processor의 등장
이제 명령어를 프로세서가 어떻게 수행하는지 조금 더 살펴보면, 모두 동일한 패턴을 따르는 것을 볼 수 있습니다.
Fetch = F:
IP가 지정한 IM 주소에서 명령어를 추출Decode = D:
명령어의 각 부분을 나누어 해석하고 제어 신호, 연산에서 활용할 데이터를 준비Execution = E:
제어 신호에 따라 적합한 연산 수행Memory = M:
메모리에 접근해서 정보를 수집하거나 메모리에 데이터를 저장하는 과정Write Back = W:
생성된 새로운 데이터를 레지스터 로드
다시 말하지만, 이 과정은 극도로 단순화한 내용입니다. 우리가 지금까지 살펴본 아주 제한적인 3개의 명령어 수준에서는 맥락상 저렇게 5개의 단계를 수행하는 것처럼 보입니다. 지금의 프로세서_v1.0은 아래와 같은 방식으로 명령어를 수행하고 있습니다.

만약 F, D, E, M, W를 수행하기 위한 하드웨어가 분리할 수 있다면, 우리는 아마 아래와 같은 방식의 프로세싱 방법을 고려해볼 수 있습니다.

Inst 1의 Fetch가 마무리된 뒤, Fetch한 명령어를 Decode 영역에 전달합니다. 이렇게 되면 Inst 1은 Fetch 영역에서 추가적인 연산을 하지 않기 때문에, Inst 2를 Fetch 영역에 입력해도 큰 문제가 되지 않습니다.
마찬가지로 Inst 1의 Decoding이 마무리된 뒤 발생한 제어 신호와 레지스터에서 불러온 데이터를 Execution 영역으로 전달하면, Inst 1은 Decode 영역에서 추가적인 연산을 수행하지 않습니다. 따라서 Fetch가 마무리된 Inst 2를 Decode영역에 입력해도 됩니다.
이러한 방식을 우리는 “파이프라이닝(Pipelining)”이라고 하는데요. 공장의 컨베이어 벨트와 비슷한 방식이라고 생각할 수 있습니다. 자동차 공장을 생각하시면 이해가 쉽습니다 — 절대로 자동차 한 대를 전부 만든 뒤에 다음 자동차를 생산하지 않습니다.
하지만 이 방법을 수행하기 위해서는 각각의 영역을 확실히 구분지을 수 있어야 합니다. 또한, 각 단계에 있는 명령어를 통해 생성된 데이터들이 서로 영향을 미치면 안됩니다. 가령, 명령어 1이 Decode 단계에 있는데, 뒤이어 Fetch된 명령어 2가 명령어 1의 Decode가 마무리 되기 전에 입력되어서는 안 됩니다. 즉, 이전 명령어의 침범을 막는 한편, 지금 Decoding 하는 명령어 1을 유지해줄 수 있는 장치가 필요합니다. 우리는 이런 장치를 활용해본 기억이 있습니다 — 바로 “셔터”입니다.
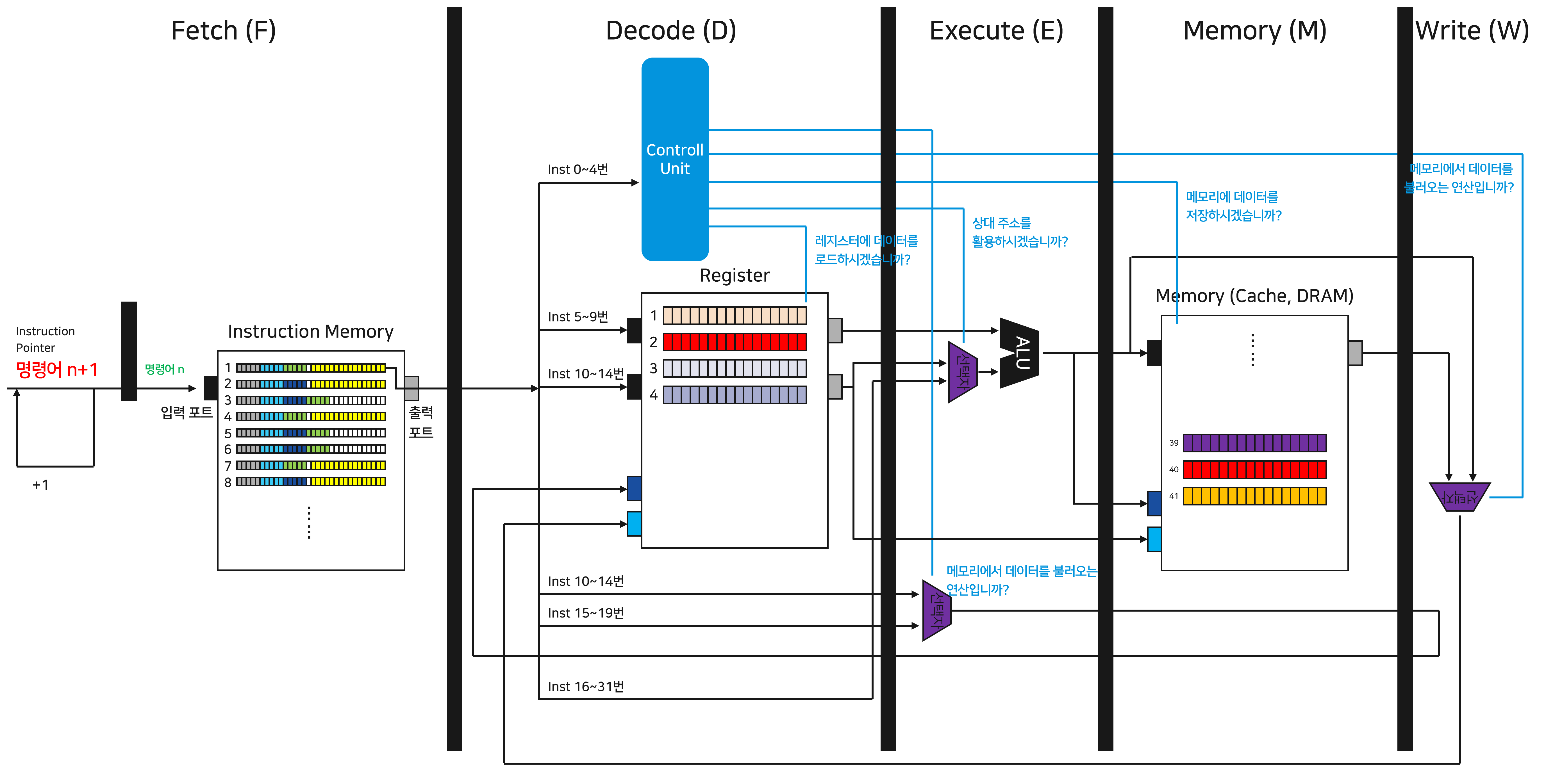
앞서서 우리는 IP에서 업데이트된 정보를 차단하기 위해 “셔터”를 활용했던 기억이 있습니다. 하나의 명령어가 완료될 때까지 다음 IP가 입력되지 않도록 하는 “셔터”를 각 단계 사이에 배치하면 우리는 멈추지 않고 작동하는 파이프라인 프로세서를 만들 수 있습니다. 이를 프로세서_v2.0이라고 명명하겠습니다.
프로세서_v2.0과 필자의 한계점
프로세서_v2.0는 또 다른 문제들에 마주치게 되는데요.
v2.0는 언급한대로 여러 개의 명령어를 쉼없이 수행할 수 있도록 설계되었습니다. 하지만 만약 첫 번째 명령어를 통해 생성된 정보를 두 번째 명령어에서 활용해야 한다면, 프로세서는 어떤 방식으로 두 번째 명령어를 수행할 수 있을까요?
더하여 우리는 지금까지 모든 명령어들을 수행하는 데 같은 시간이 필요하다는 가정 하게 설계를 진행했습니다. 하지만 이는 틀린 가정입니다. 만약 첫 번째 명령어를 처리하는데 아주 오랜 시간이 필요하다면 뒤이어 오는 명령어는 어떻게 수행해야 할까요?
마지막으로 특정 조건에 따라 명령어의 순서가 바뀌는 경우도 있습니다. v2.0의 IP는 매 Cycle마다 숫자를 1씩 늘려 바로 다음 명령어를 가리키는데요. 경우에 따라 20번째 뒤에 위치한 명령어를 수행해야 할 수도 있습니다. 만약 이를 정확히 예측하지 못해 사이에 위치한 19개의 명령어를 수행한다면, 모든 수행 결과를 버려야 하는 슬픈 상황이 생깁니다.
이러한 문제를 해결하기 위해서 우리는 Data Forwarding(v3), Reorder Buffer(v4), Reservation Station(v5), Branch Prediction(v6)이라는 다른 개념을 도입할 계획입니다.
필자의 한계점: 다만… 이번 포스팅에서는 v2까지만 만들고 잠시 쉬어가도록 하겠습니다. 단순화된 예시로 그림을 그리고, 간단히 설명하는 것이 쉽지 않습니다. 다만, 이 포스팅에 계속해서 위 개념들을 추가할 예정이니 종종 프로세서_v6.0을 기대하며 방문해주시면 감사하겠습니다.
아, 넘어가기 전에. v3~v6 과정에서 차용하는 모든 개념은 사실상 “연산”과는 관련이 없습니다. v2.0까지 설계하는 과정에서도 언급했듯, 대부분은 명령어 제어에 그 방점이 찍혀 있습니다.
CPU는 왜 딥러닝에 적합하지 못한가?
저도 CPU는 태어나서 처음 공부해보았습니다. 지금까지 저는 CPU의 발전 과정에서 연산이 그 핵심에 있었을 것이라고 생각했었는데요. 물론 연산의 발전사가 없는 것은 아니나, 오늘의 포스팅처럼 대부분은 “명령어 제어”에 힘을 쏟습니다. 그리고 이는 수천~수만 개의 명령어를 문제 없이 수행하기 위한 필수 단계일지도 모릅니다.
실제로 앞서서 언급했던 Fetch, Decode, 아직은 자세히 설명하지 않은 Reorder Buffer, Reservation Station 등의 개념은 최근에 발표된 Intel CPU에서도 차용하고 있습니다. 아래 그림은 21년 발표된 Intel의 Golden Cove Core의 Microarchitecture인데요. 프로세서_v6.0 정도가 되면 인텔의 구조와 얼추 비슷한 모양새가 나올 것으로 보입니다.
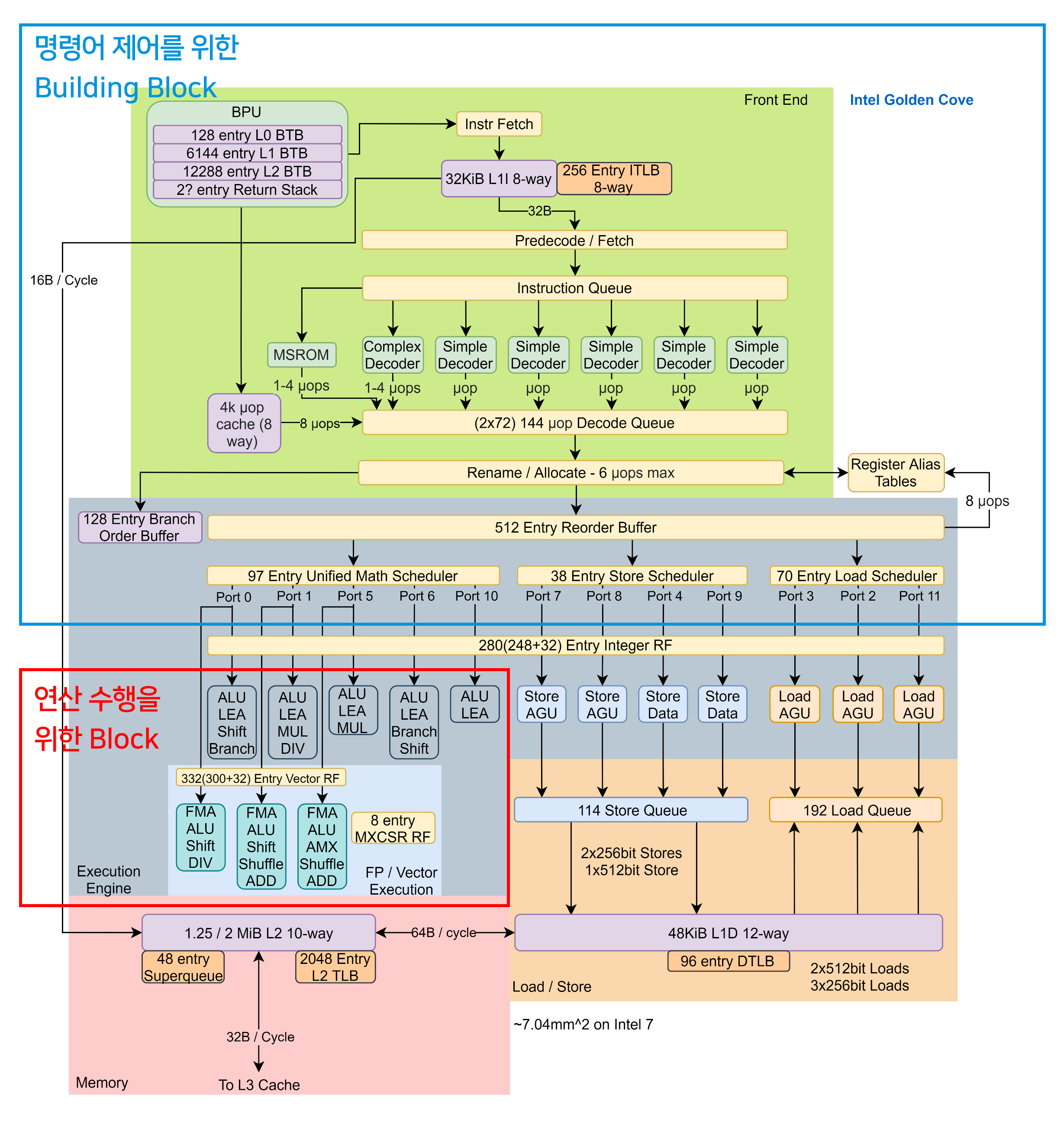
여기서 우리는 왜 CPU가 인공지능 연산에 적합하지 않은지 확인할 수 있게 됩니다. 그림에서 볼 수 있듯, CPU는 꽤 많은 부분을 “명령어 제어”에 할애하고 있으며, 연산 수행을 위한 영역은 제한적입니다. 위 그림에 표시하지 않은 부분은 “메모리 접근”과 관련된 역할을 하는데요. 이러한 구조를 볼 때 CPU는 “공장보다는 Headquarter”에 가깝다, 라고 설명해볼 수 있겠습니다.
이번 포스팅 시리즈에서 딥러닝 연산 자체에 대해 다루지는 않겠습니다만, 딥러닝 연산의 대부분은 행렬곱(Matrix Multiplication)으로 이루어져 있습니다. 그리고 행렬곱은 독립적인 덧셈과 곱셈으로 이루어져있습니다. 따라서 굳이 다양한 명령어가 필요하지 않고, 명령들 사이의 종속성을 고려한 복잡한 명령어 제어 과정이 상대적으로 중요하지 않습니다. 딥러닝과 CPU가 중요하게 생각하는 기능이 다른 만큼, 딥러닝 연산에 적합하지 않음은 직관적으로 이해할 수 있습니다.
지금까지 아주 간단한 구조의 CPU를 만들어보며 “왜 CPU가 딥러닝에 적합하지 않은지”를 설명해보았습니다. 다음 포스팅에서는 구글의 TPU에 대해 다룹니다. TPU는 어떤 구조를 가지는지, CPU와는 어떤 차이가 있는지, 왜 딥러닝 연산에 더 적합한지 상세히 설명해보도록 하겠습니다. 모두 긴 글 읽어주셔서 감사합니다!